Improving Git Workflows A Developers Journey With Friends
Intro, Ron’s assigned a project
This article will go through the character development of a typical developer with their arguably most important workflows - git
Meet Ron, he's a 3rd year college student just beginning his journey as a developer. He's just been assigned to work on a project with peers, and they are supposed to work together on the codebase.

Let’s say he has sensible teachers, and is building the project in go. So he goes and starts a fresh project with a main.go
He's like, "Okay, we need to write some code, let's download an editor first"... and they go and get vscode or one of it's "ai" flavours off the internet
He needs a collaborator
Now he asks his friend Harry for help setting up a web server. Harry's a little further along the wizarding world and asks him to set up a github repository. Ron goes ahead and does that
note: I’m using gitea here, cuz it’s easier to set up multiple accounts locally… just assume it’s github
Configuring git
At this point, Ron would be good to push his first commit, but just then, their friend Hermioni steps in and tells him to be a good developer, and sign your commits
She helps him set it up with a few simple steps, like so…
opensshssh-keygen -t ed25519 -C "ron@mail.com"~/.ssh/config
Host rongit
HostName localhost
Port 30022
User git
IdentityFile ~/.ssh/gitblog/ron
.gitconfig in the home directory[user]
name = ron
email = ron@mail.com
signingkey = ~/.ssh/gitblog/ron
[commit]
gpgsign = true
[gpg]
format = ssh
[credential]
helper = store
ron.pub to github 

Optional: Here’s a neat trick I use to segragate work/personal projects, or act as Ron, Harry in this case.
You specify an
includeIfdirective in your git config like so, git automatically switches identities when you are in the specified directory 🪄
Now he can go to github and create a new empty repository for his project
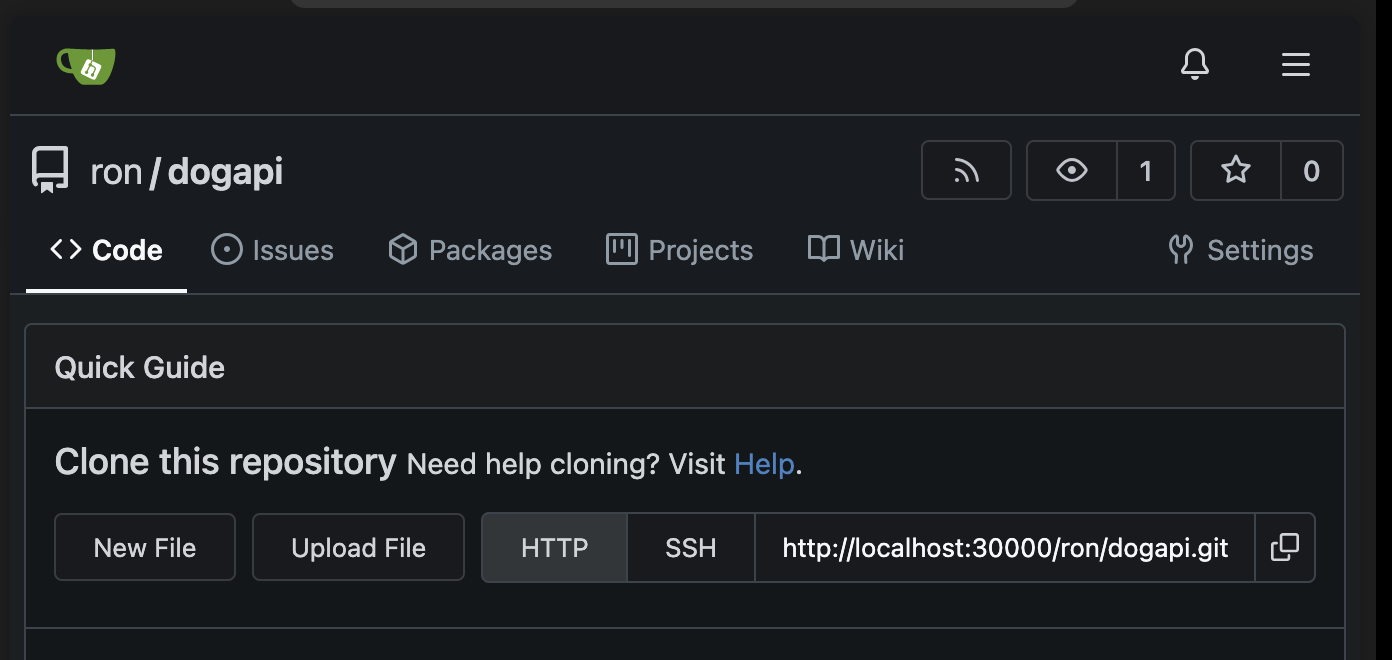
Add it as remote origin to his local repository
Again, would be github in a normal scenario…
1
2
3
4
5
Desktop/ron/dogapi
❯ git init
Initialized empty Git repository in /Users/ashu/Desktop/ron/dogapi/.git/
dogapi on main ?
❯ git remote add origin rongit:ron/dogapi
He’s now ready to push his initial commit using vscode’s vcs feature
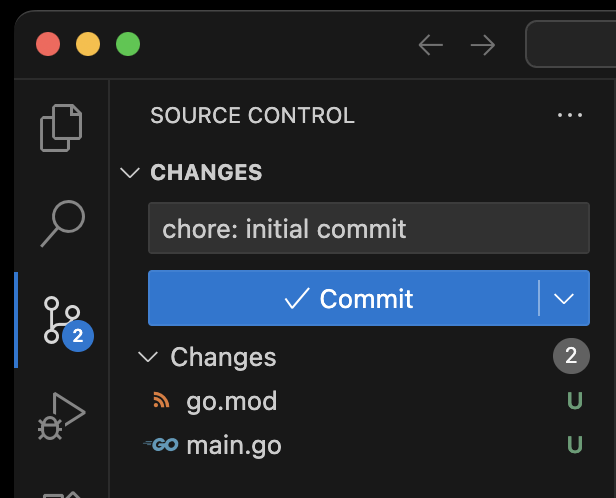
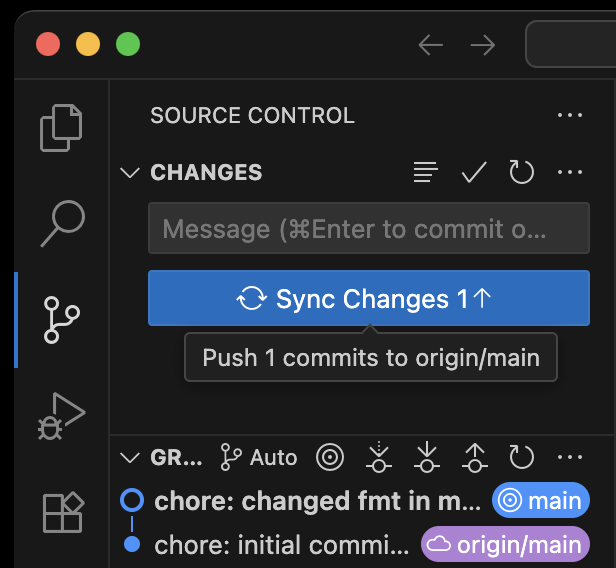
 That’s it, his repo is now ready for Harry to add his changes…
That’s it, his repo is now ready for Harry to add his changes…
This is where most folks stop, and if not for friends/co-workers like Hermioni here, people end up skipping the important step of setting up ssh for authentication and commit signing as well, and just make do with PAT tokens, which can either be a pain to refresh every once in a while, or be a clear security risk.
There is a use case for PAT’s, but day to day developer workflow is not one, in my opinion… especially if you do not want to, or can’t skip the commit signing process
Anyway, let’s move on to see what Harry’s up to
P.S. I ended up deciding on the potter references a bit later… my Ron wears specs as well ;)
Harry’s fork
Harry was asked to add an api server for the team, and Ron gave him the repository link http://localhost:30000/ron/dogapi
First thing harry does, is fork Ron’s repo on github 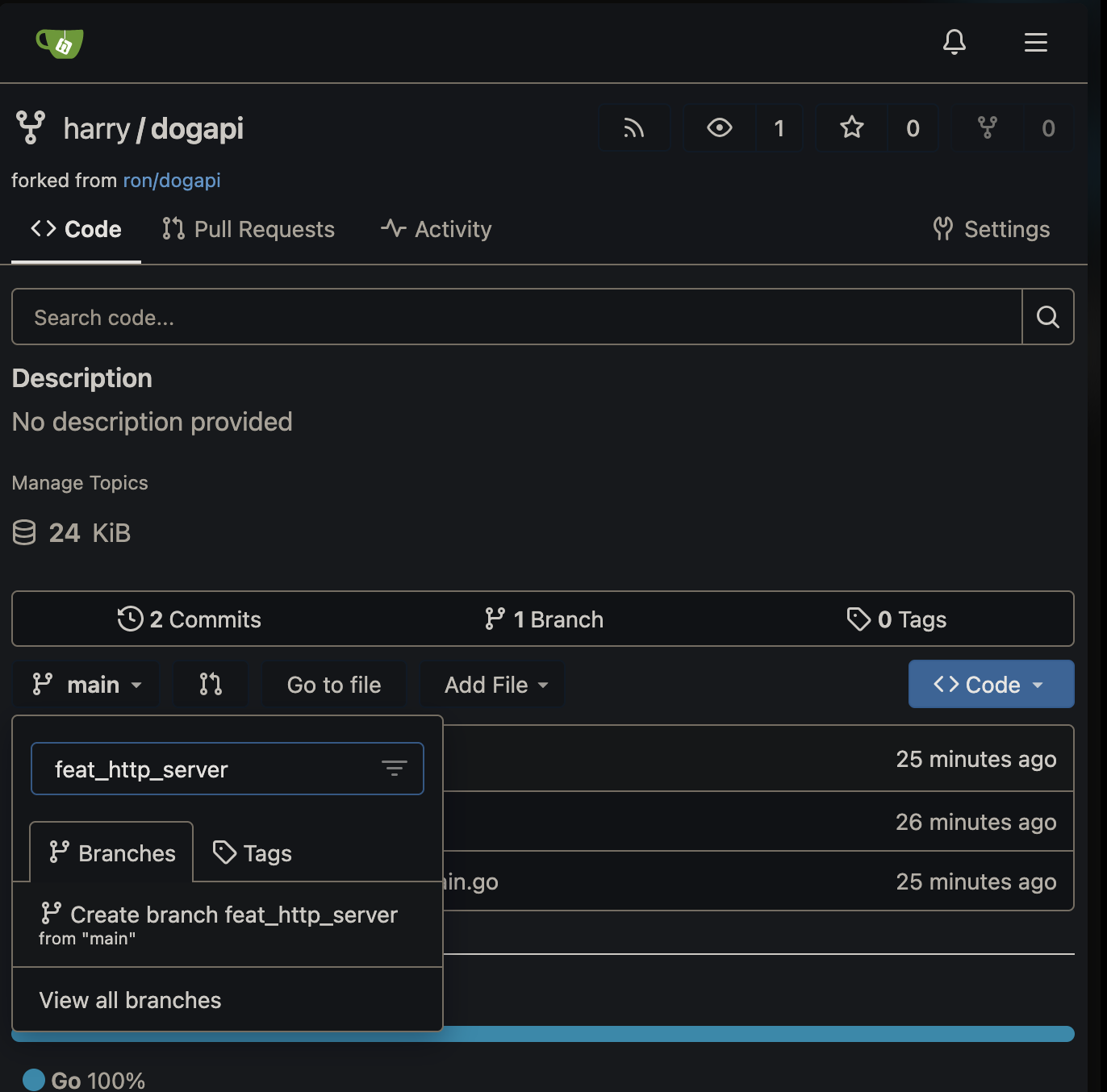
He then clones this fork locally, and checks out the necessary branch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
❯ git clone git@harrygit:harry/dogapi
Cloning into 'dogapi'...
remote: Enumerating objects: 7, done.
remote: Counting objects: 100% (7/7), done.
remote: Compressing objects: 100% (6/6), done.
remote: Total 7 (delta 1), reused 0 (delta 0), pack-reused 0 (from 0)
Receiving objects: 100% (7/7), done.
Resolving deltas: 100% (1/1), done.
~/Desktop/harry
❯ cd dogapi
dogapi on main
❯ git checkout feat_http_server
branch 'feat_http_server' set up to track 'origin/feat_http_server'.
Switched to a new branch 'feat_http_server'
dogapi on feat_http_server
Then he quickly whips up a simple http server template for ron. He wasn’t told much though, so he adds a single endpoint and doesn’t bother with any package structure 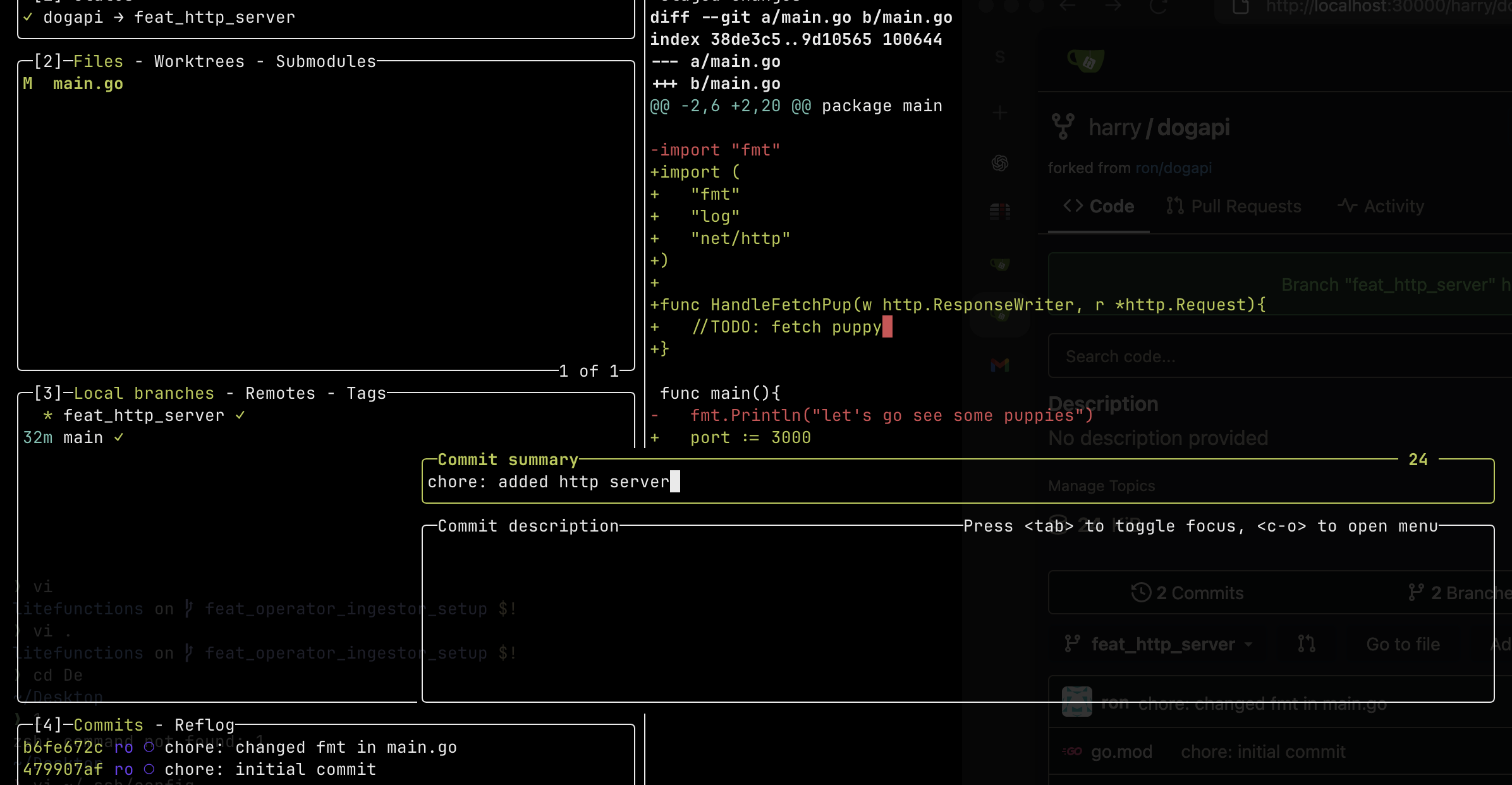
The tool he’s using here, might seem overwhelming if you are new, but it’s probably one of the easiest tool to use.
Here’s all you need
- Install it with
go install github.com/jesseduffield/lazygit@latest- Open it with the command
lazygit- It’ll show all unstaged files on the left
- press
cto start a commit, put your message- press
pto pull, andshift-pto push
Well, it is.. if you understnad git, otherwise the add and sync UX of vscode or github desktop does seem more appealing. Not diving into the git concepts and commands in much detail here, there are plenty of resources for it out there. We will definitely go through what’s necessary
Now Harry needs to send his changes to Ron, he does this by creating a pull request, like so 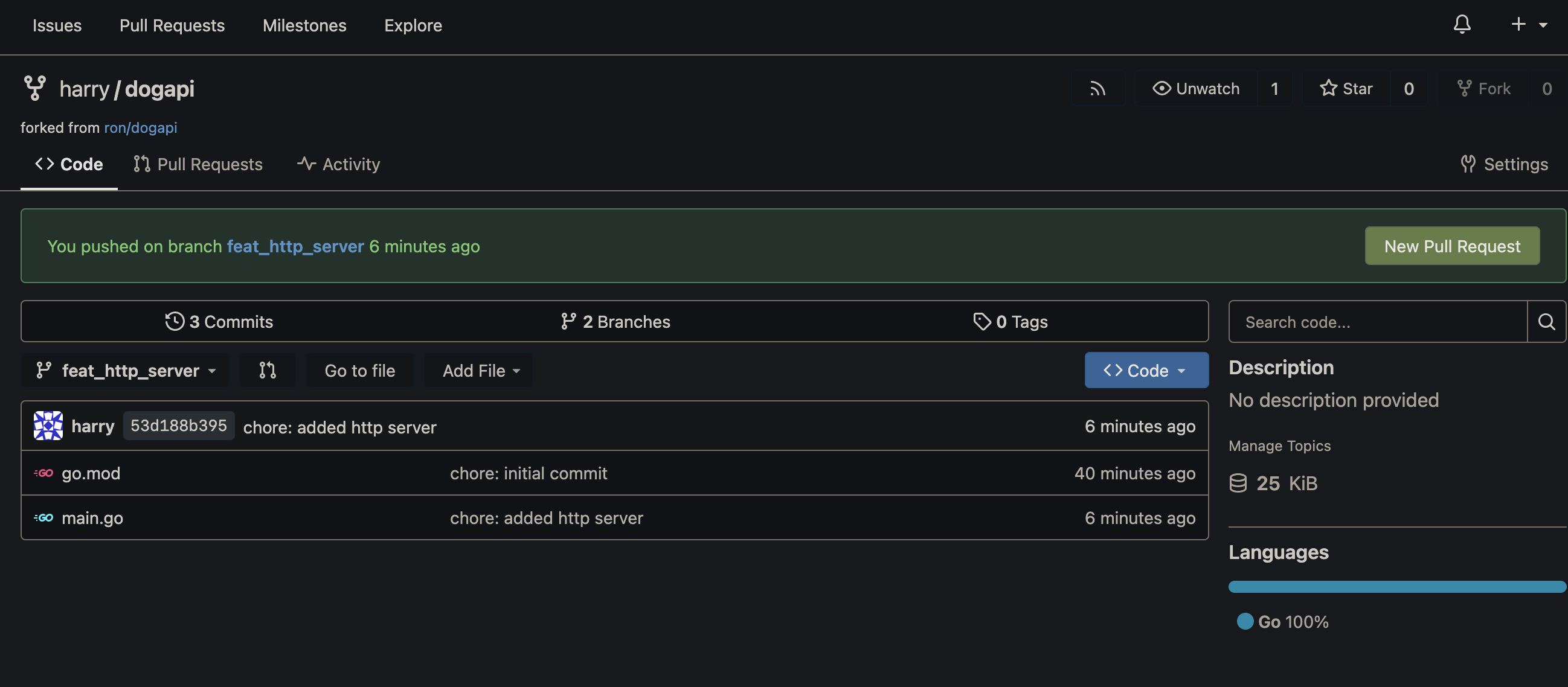
Note, in this case, the pull/merge request is being raised from harry:feat_http_server to ron:main. In case of private repos, which are more commonplace at work, the fork step would be replaced with an admin giving Harry access to the repo and the PR being from feat_http_server to main in the same repository
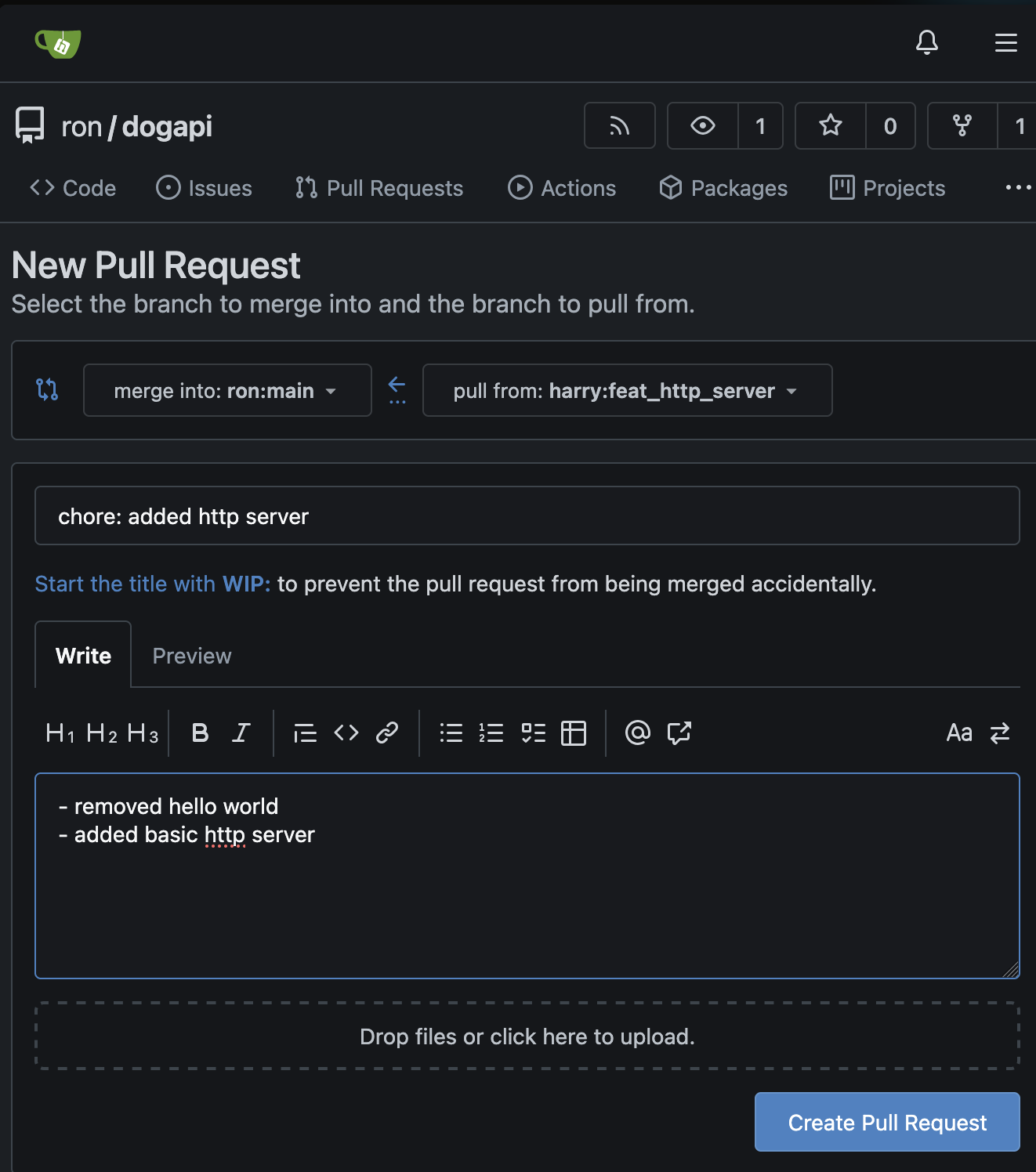
Harry sends this request to Ron: http://localhost:30000/ron/dogapi/pulls/1
PR Reviews
Now, Ron has to check if the PR does what he had asked for. He opens the link and goes through it.
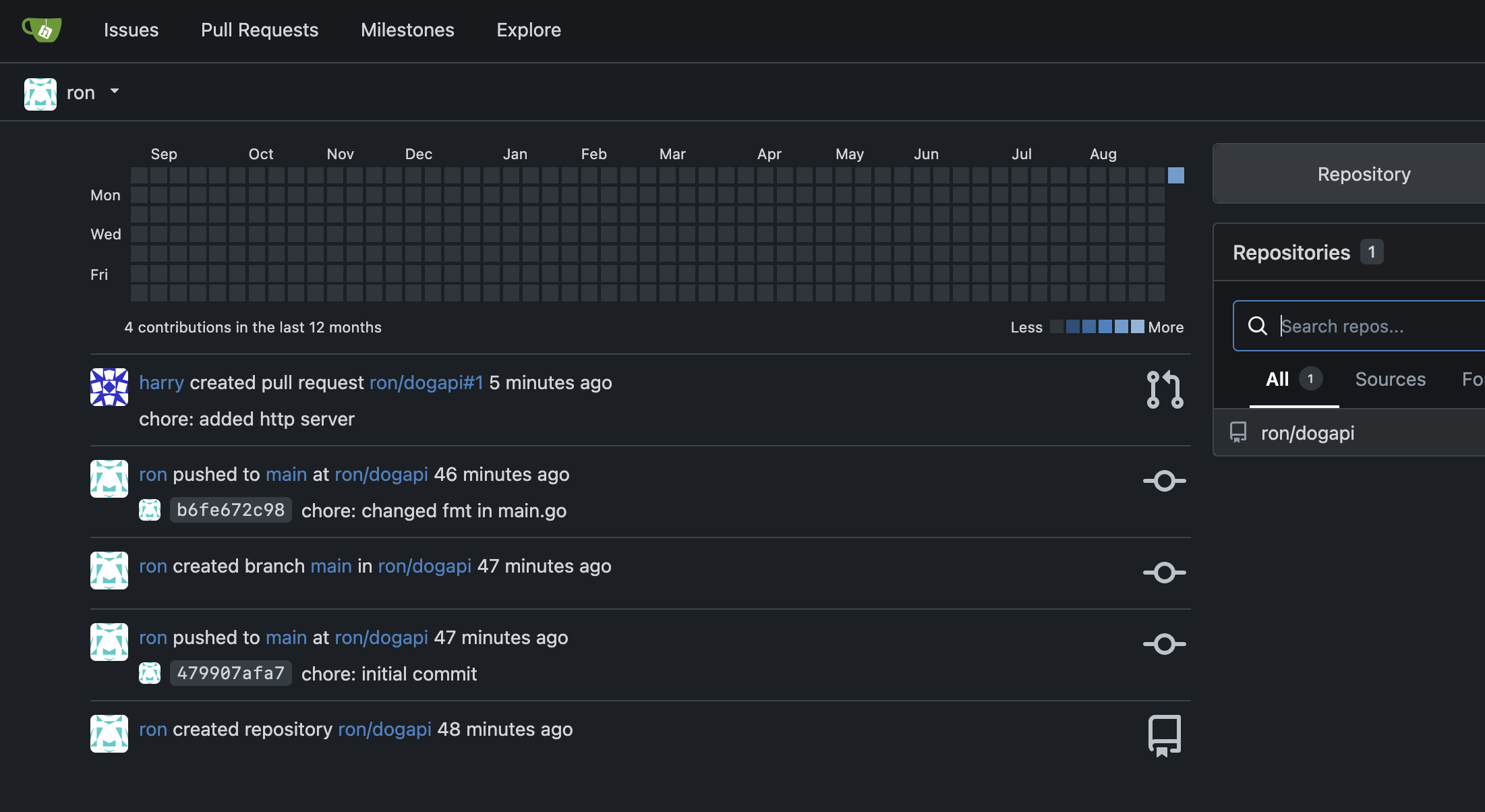
Meanwhile Harry realized a bug in his code, and fixes it in the same feature branch, Ron gets notified of the same
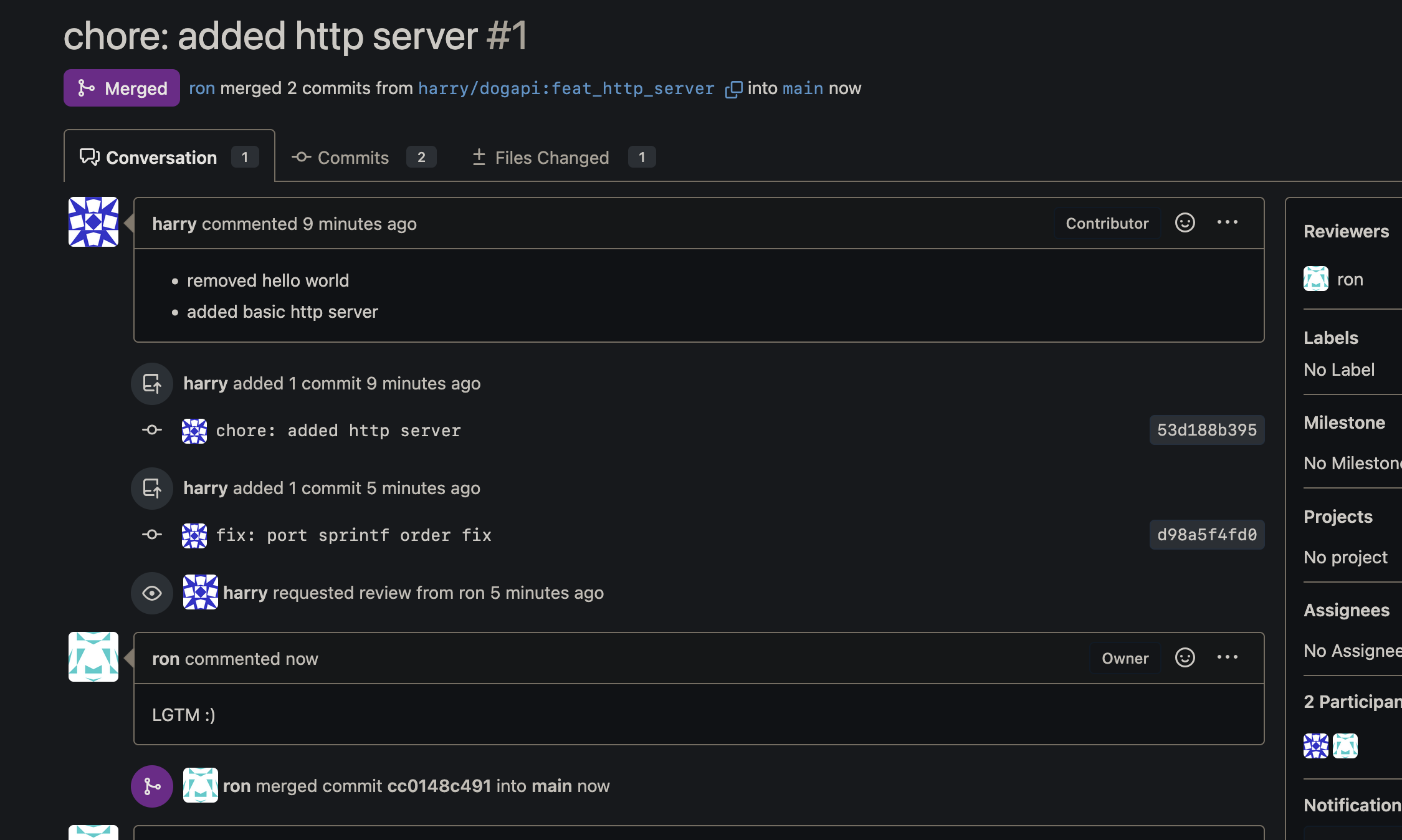 Ron, blindly accepts the PR, and merges it into main
Ron, blindly accepts the PR, and merges it into main
And there we go again…
Hermioni notices this and decides to have a talk with the two
What happened here is a typical developer flow most of the time, and it's totally understandable. Ron made a simple request, and harry delivered. It may be totally fine in small teams where there's enough face to face discussions and trust... but does not scale beyond that

PR best practices
Without getting too preachy about it, here’s what entails a good pull request workflow
- It’s meant to be a conversation, not a two factor approval process
- If requirements are unclear, that’s fine.. create an issue and maybe link an external document there
- Once raised, a pull request does not need to be merged immediately, testing and review can and should continue in the feature branch
- Any fixes or changes to the code may happen in the same tree, or branch into a seperate feature branch if needed
- Not everything raised in a PR need to be resolved immediately, it can spawn issues and tasks for the future
- Certain merges would take priority, e.g. if there’s a major refactor changing the tree structure and is a dependency for certain features
- Bottom line, it’s not a place to prove others wrong, just to point out things that can be fixed
- PR’s should be marked appropriately if they are intended to stay open for the course of, say a sprint
- There should ideally be CD in place to spin up ephemeral integration test environments from the feature branch if needed
- Merging a PR is a not the approver’s responsibility alone, but everyone involved in the discussion
The planning phase
Anyway, getting back to RON..
So Hermioni helped him create an issue with a rough proposal document, there are various terms for these, be it SDS, RFD or enhancement proposals like most open source projects, i.e. KEP, PEP, etc
There's no need for every project to be organizational and rigid, but there should be some conception of a plan

So ron went ahead and created a github issue with the requirements
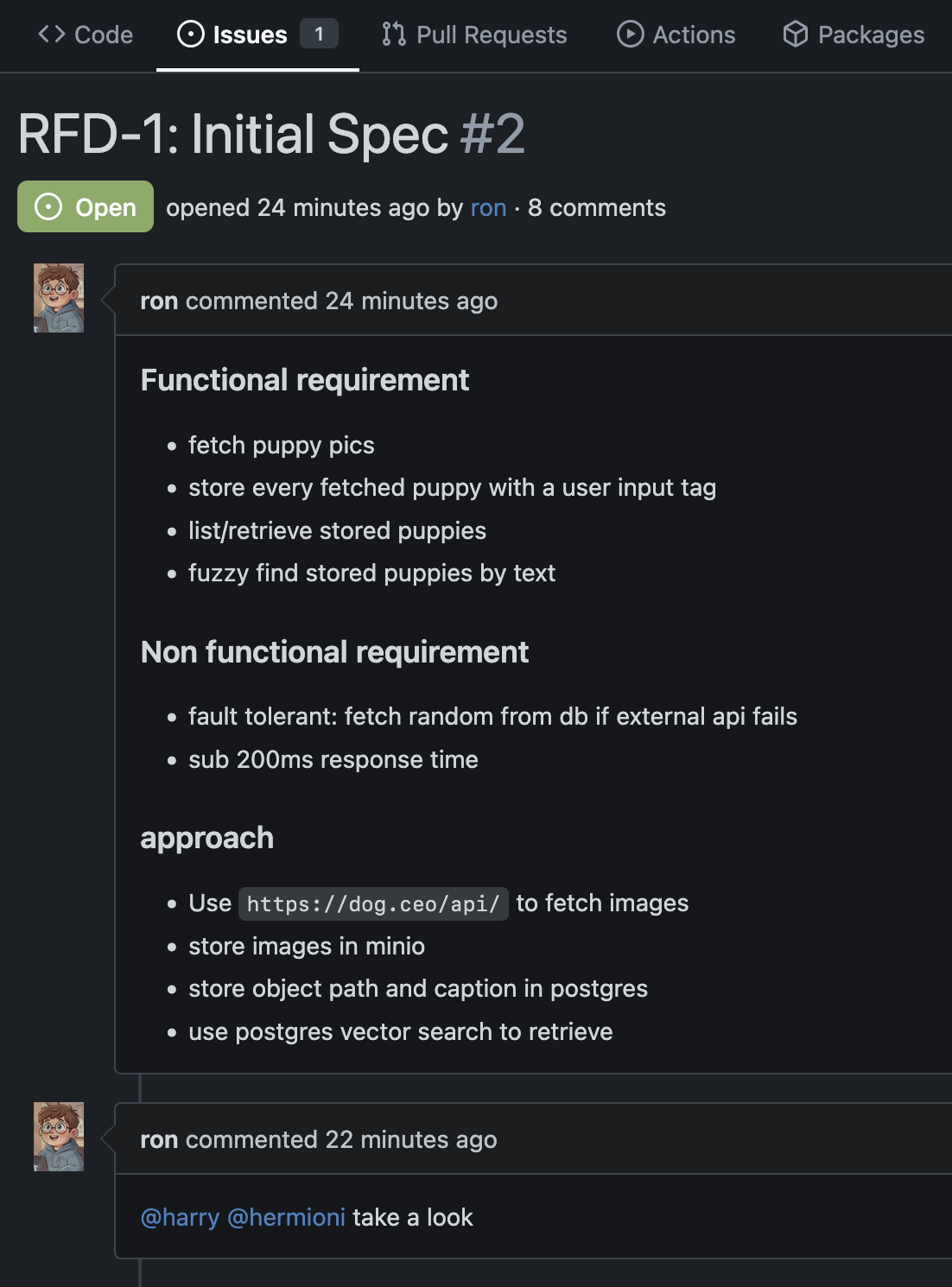
Hermioni goes through it, and asks Harry for his insights.

Harry gives it a thought, whips out excalidraw and draws a rough sketch describing the following
- api spec
- failure points
- rough data flow/ api logic
- internal/external dependencies
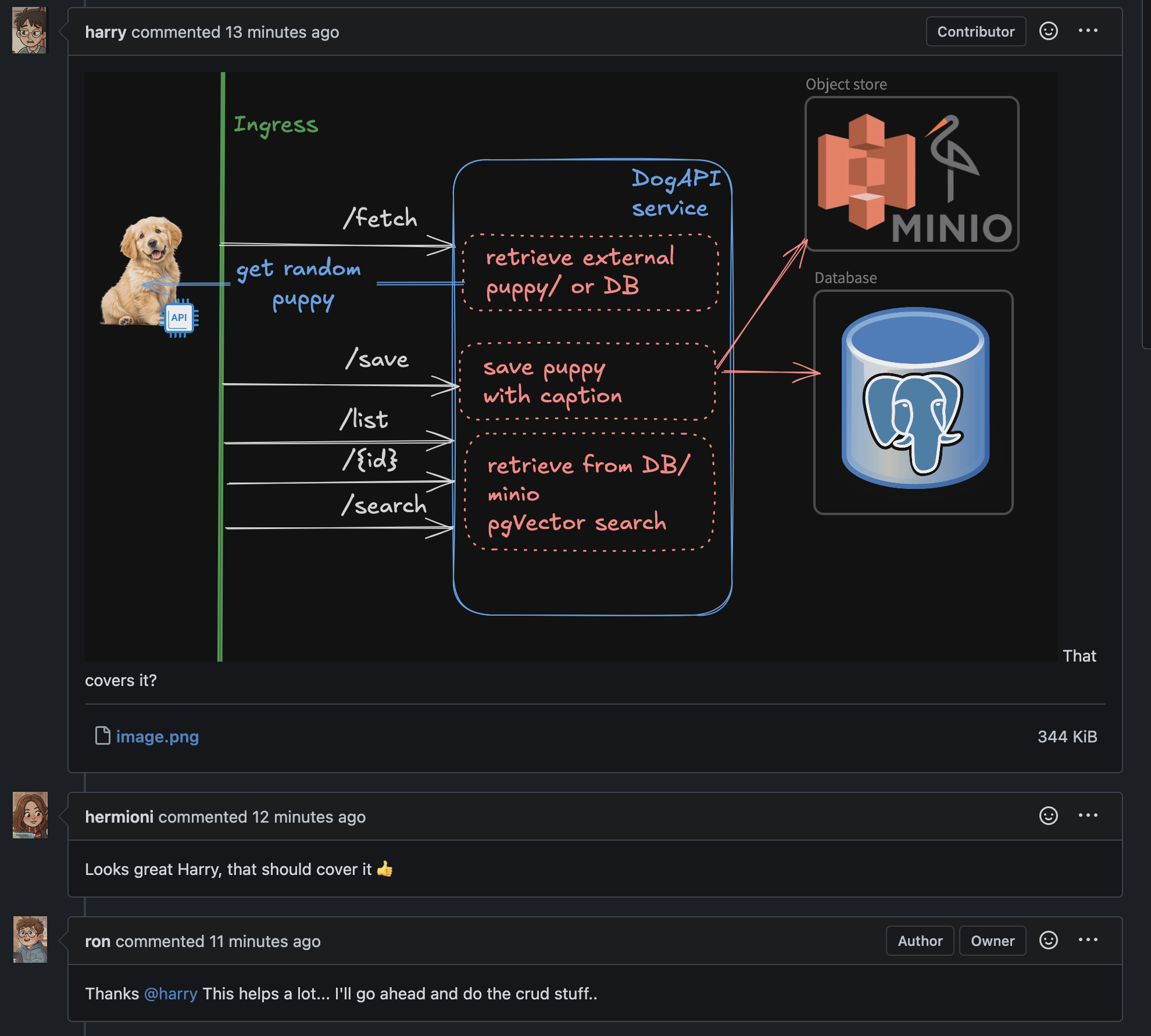
Ron then looks at the current codebase and realizes there’s no state management, or any scaffolding built right now and needs Harry’s help
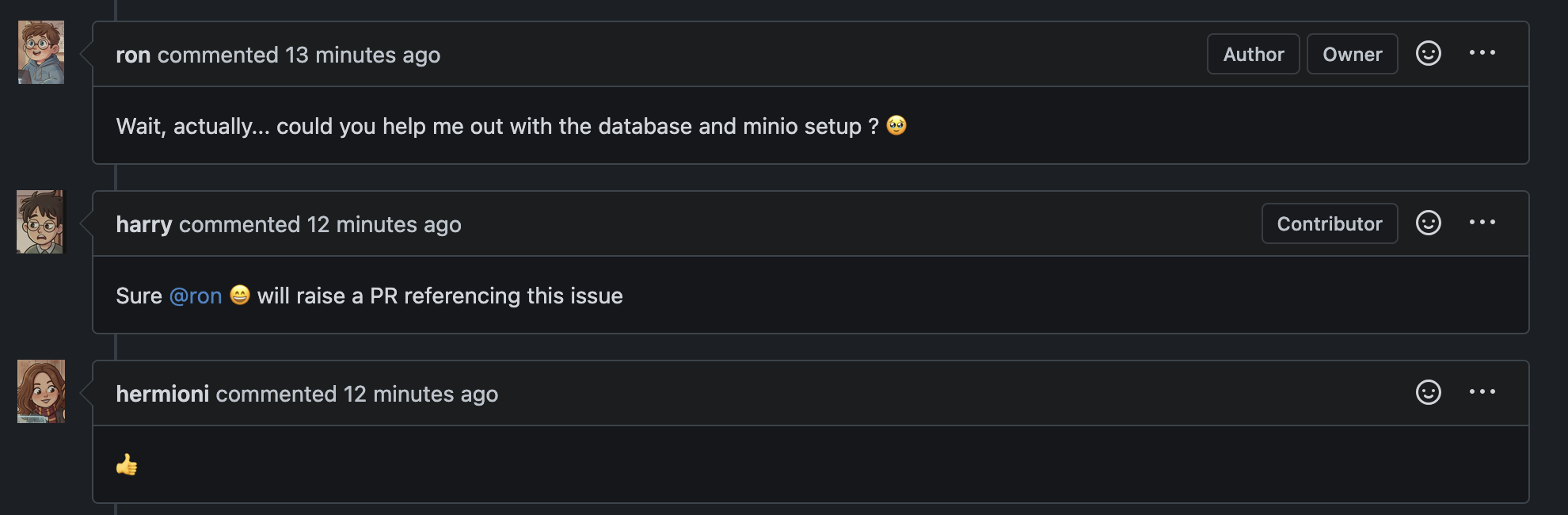
Task distribution and collaboration
Note how Ron didn’t hesitate to ask for help when needed? And since he was clear what Ron needed, Harry took on the task of setting up the package structure, and state management.
Now it’s time to code that up… Harry started with a package structure, and used a few dependencies to set up settings and minio connector, and defined the handlers as planned. Then he goes and raises his PR
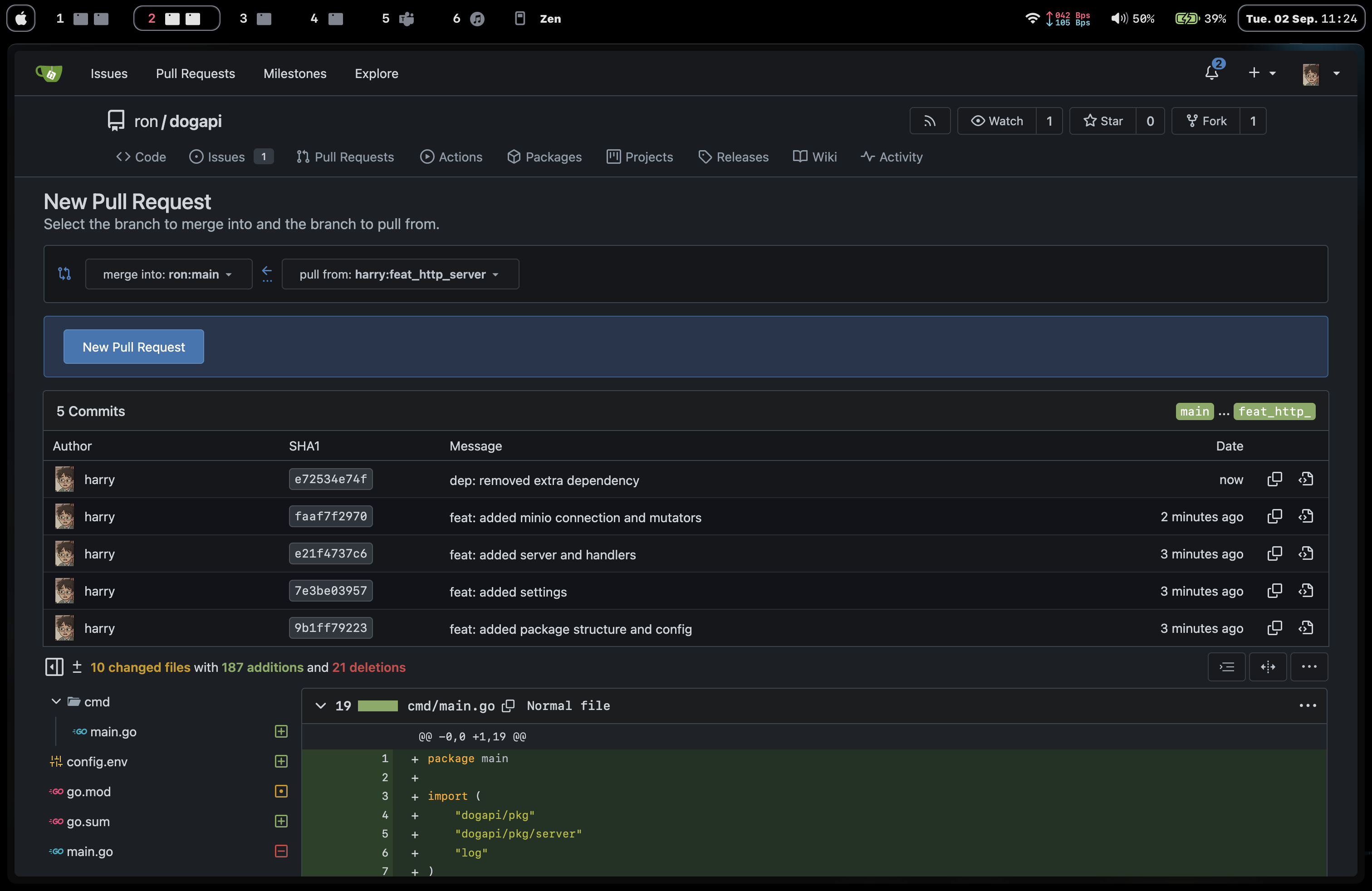
He needs to add a description of the changes in the pull request
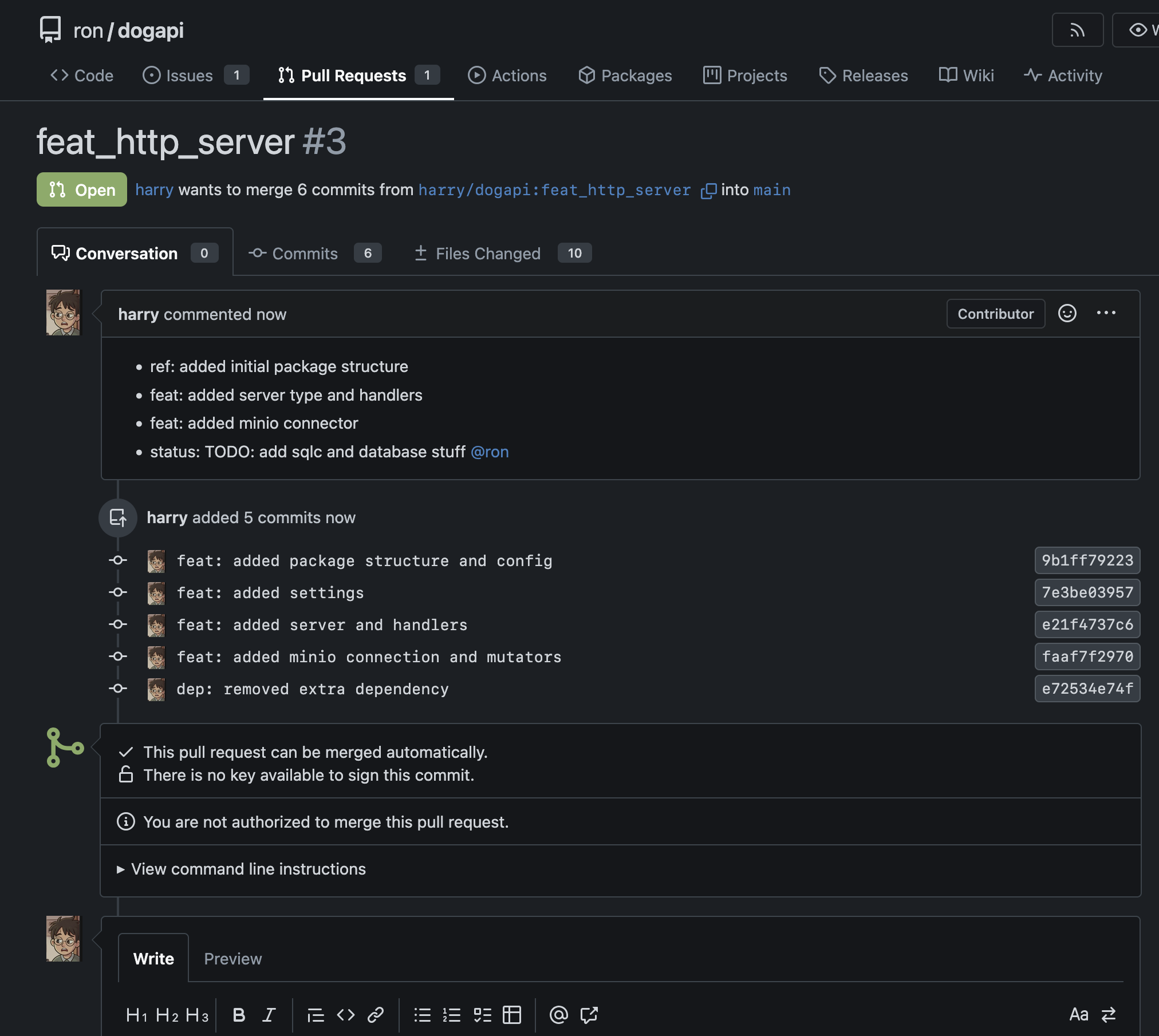
For the minio connector, he was stumped between using the s3 connector from aws and the client package from minio, cuz he had better experience from the aws one in other languages, in the past. He left a comment stating the same and why he chose to go with the latter

Now it’s time for Ron to do his part, but he asked hermioni to take a look as well. They then decided to pull in the professor for a second opinion
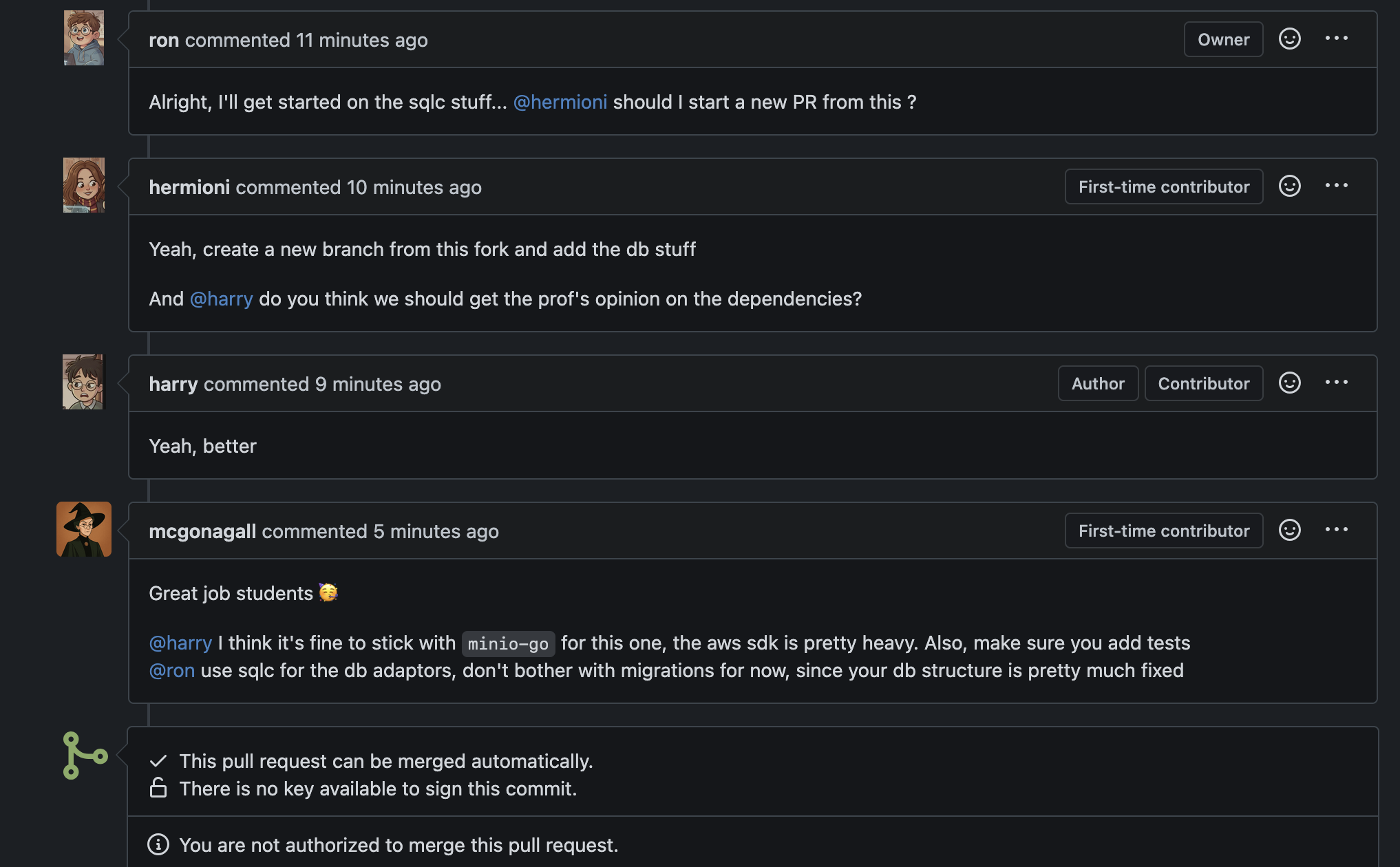
Don’t hurry to merge PRs
Ron now needs to create his branch for the business logic, off harry’s feature branch. Usually in a private repo, he could just checkout harry’s feat_http_server branch and checkout -b from there. But this is a bit unusual, where he needs to create a branch off harry’s fork. He can do so by adding a second origin, like so…
Add harry’s fork as a second origin to the local repo
1
❯ git remote add harryfork rongit:harry/dogapi
Fetch harry’s branches
1
2
3
4
5
6
7
8
9
❯ git fetch harryfork
remote: Enumerating objects: 28, done.
remote: Counting objects: 100% (28/28), done.
remote: Compressing objects: 100% (23/23), done.
remote: Total 26 (delta 8), reused 0 (delta 0), pack-reused 0 (from 0)
Unpacking objects: 100% (26/26), 5.80 KiB | 848.00 KiB/s, done.
From rongit:harry/dogapi
* [new branch] feat_http_server -> harryfork/feat_http_server
* [new branch] main -> harryfork/main
Merge Harry’s feat_http_server branch into his local main
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
git merge harryfork/feat_http_server
Updating cc0148c..a9efdc4
Fast-forward
cmd/main.go | 19 +++++++++++++++++++
config.env | 4 ++++
go.mod | 16 ++++++++++++++++
go.sum | 42 ++++++++++++++++++++++++++++++++++++++++++
main.go | 21 ---------------------
pkg/adaptors/mutators.go | 2 ++
pkg/adaptors/selectors.go | 2 ++
pkg/conf.go | 36 ++++++++++++++++++++++++++++++++++++
pkg/server/handler.go | 26 ++++++++++++++++++++++++++
pkg/server/state.go | 40 ++++++++++++++++++++++++++++++++++++++++
10 files changed, 187 insertions(+), 21 deletions(-)
create mode 100644 cmd/main.go
create mode 100644 config.env
create mode 100644 go.sum
delete mode 100644 main.go
create mode 100644 pkg/adaptors/mutators.go
create mode 100644 pkg/adaptors/selectors.go
create mode 100644 pkg/conf.go
create mode 100644 pkg/server/handler.go
create mode 100644 pkg/server/state.go
Create a new branch for the business logic and push to origin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
❯ git checkout -b feat_db_adaptors
Switched to a new branch 'feat_db_adaptors'
dogapi on feat_db_adaptors $
❯ git push --set-upstream origin feat_db_adaptors
Total 0 (delta 0), reused 0 (delta 0), pack-reused 0
remote:
remote: Create a new pull request for 'feat_db_adaptors':
remote: http://git.example.com/ron/dogapi/pulls/new/feat_db_adaptors
remote:
remote: . Processing 1 references
remote: Processed 1 references in total
To rongit:ron/dogapi
* [new branch] feat_db_adaptors -> feat_db_adaptors
branch 'feat_db_adaptors' set up to track 'origin/feat_db_adaptors'.
Notice how there was no hurry to merge the existing PR?
Ron can proceed with his changes while Harry and others work on unit tests and other things parallely. Git it really amazing for asyncronous workflows like this, but most people just avoid it and rely on slack channels or word of mouth syncronous operations… no better than google drive
Asyncronous work
While Ron and Harry are busy building the service, Hermioni can parallely start a new flow for the deployment and CI/CD part
Note: day to day git workflows are usually more straightforward than this, e.g. deployment wouldn’t start until initial merge, but I’m trying to cover as much base as possible
She can follow the same steps that Ron did, or just fork Ron’s branch… 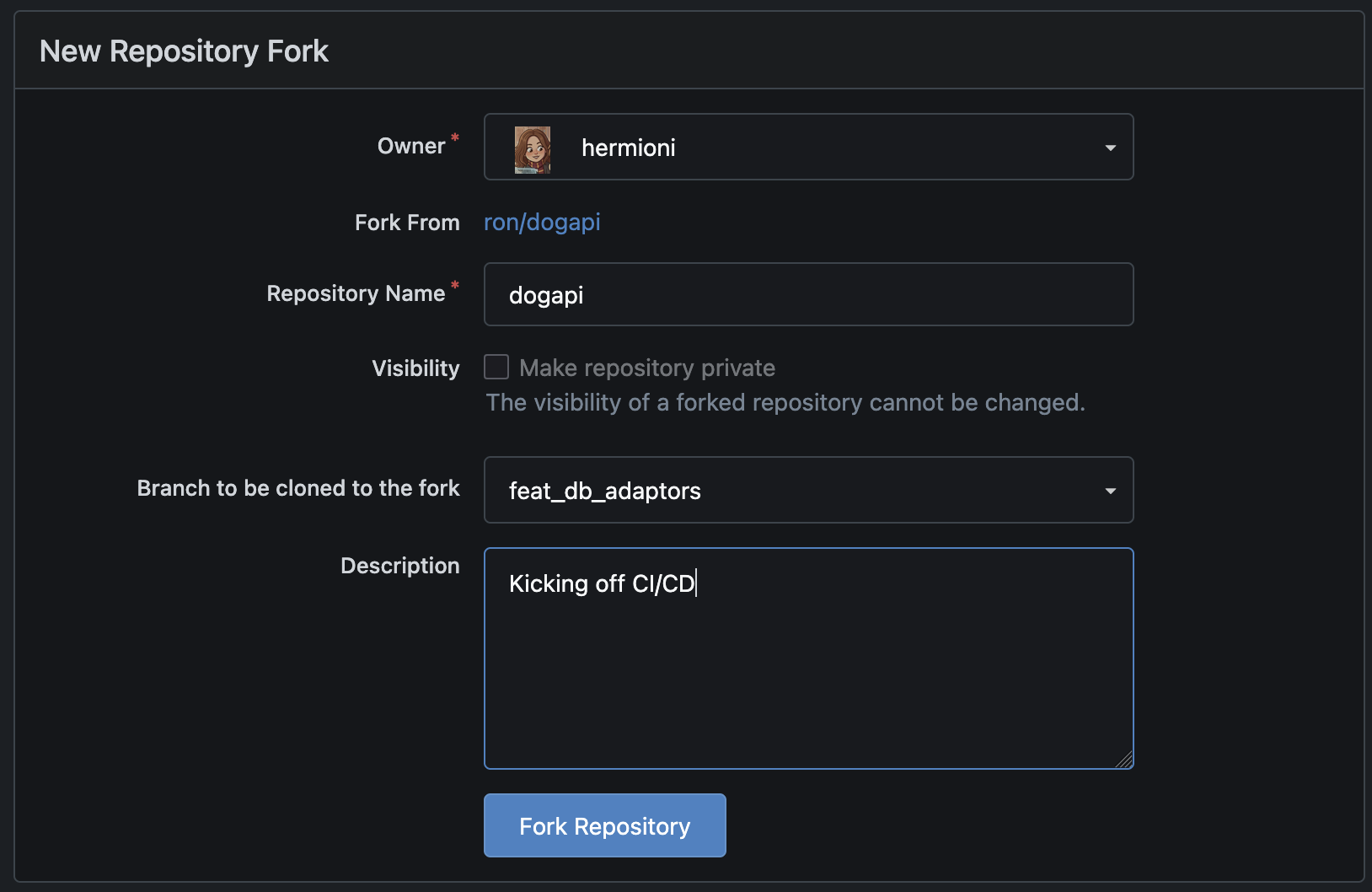
She quickly added template github actions and dockerized the service 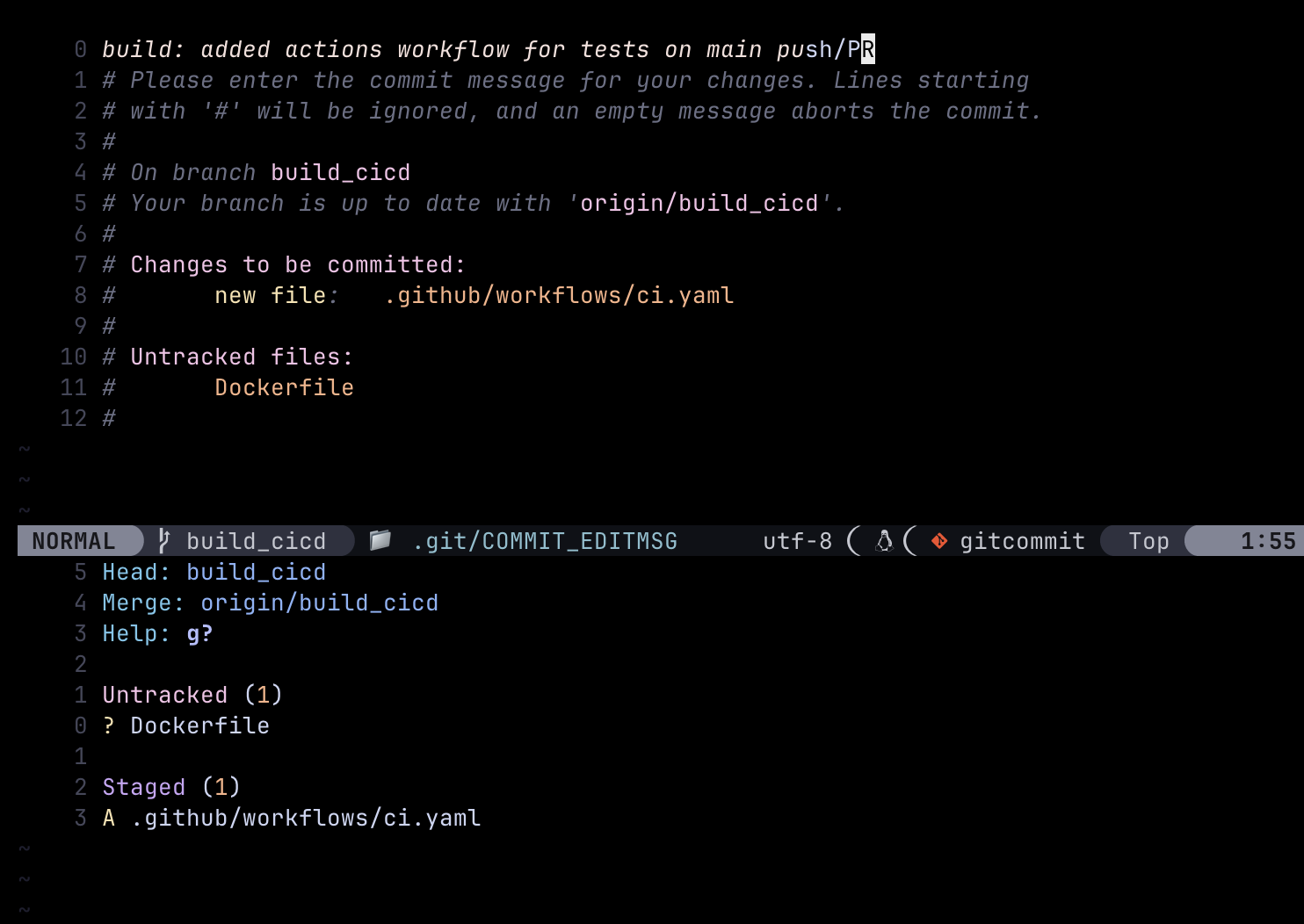
Instead of lumping a full change into a single commit, sperating files or hunks into individual commits should be considered when appropriate
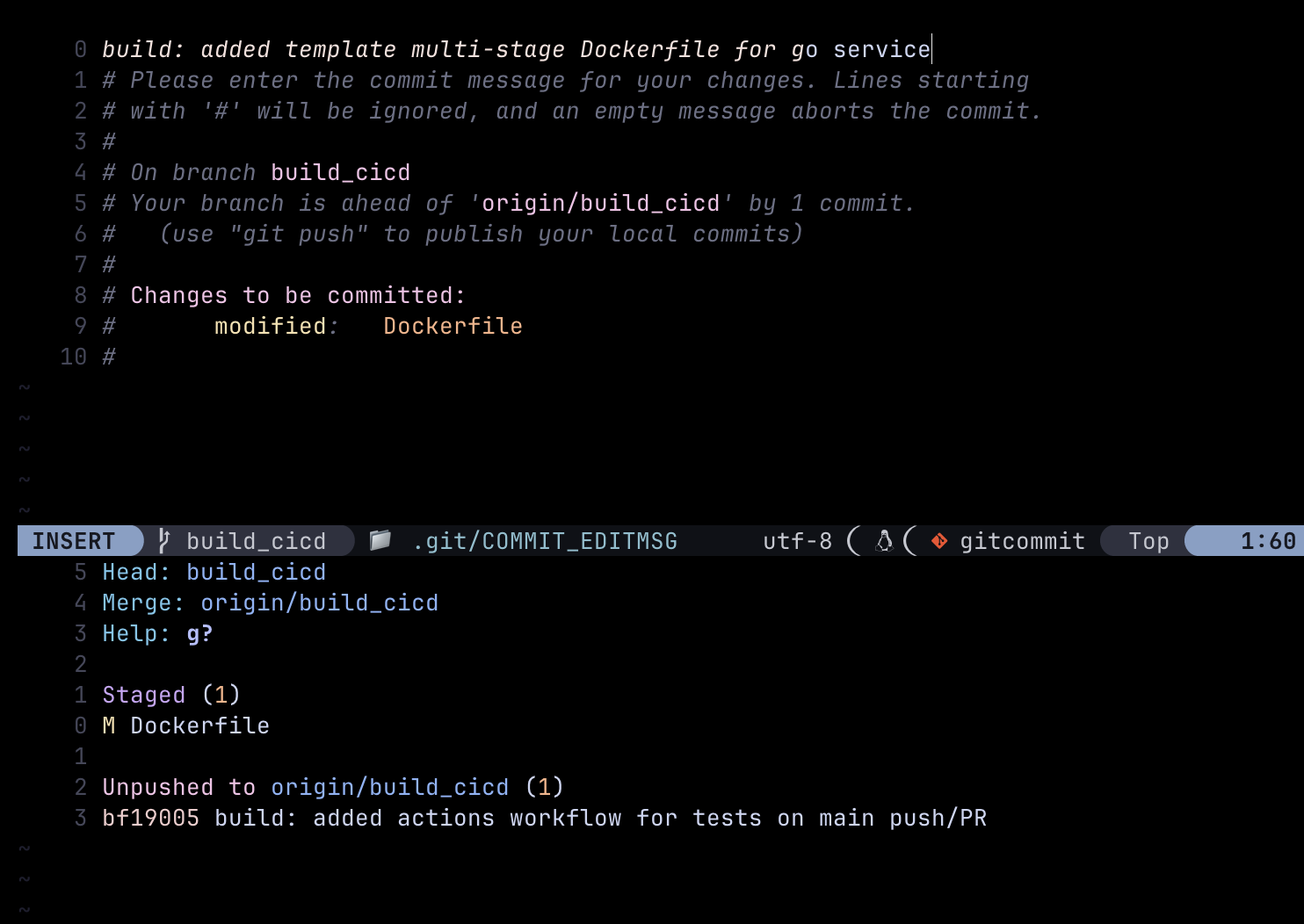
Then she raised the PR to Ron’s feature branch 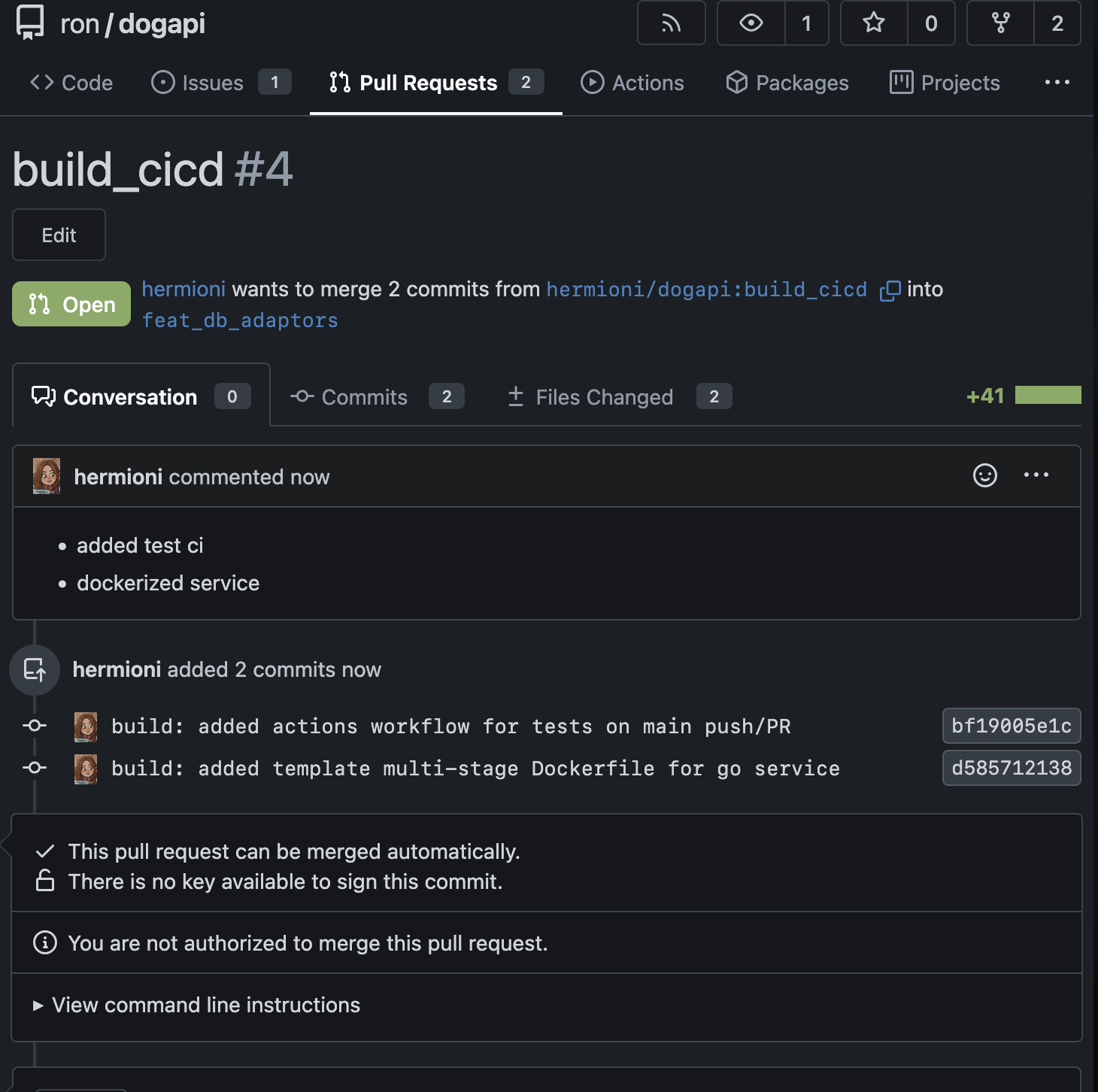
Meanwhile, Ron created a new RFD issue to discuss the full text search approach 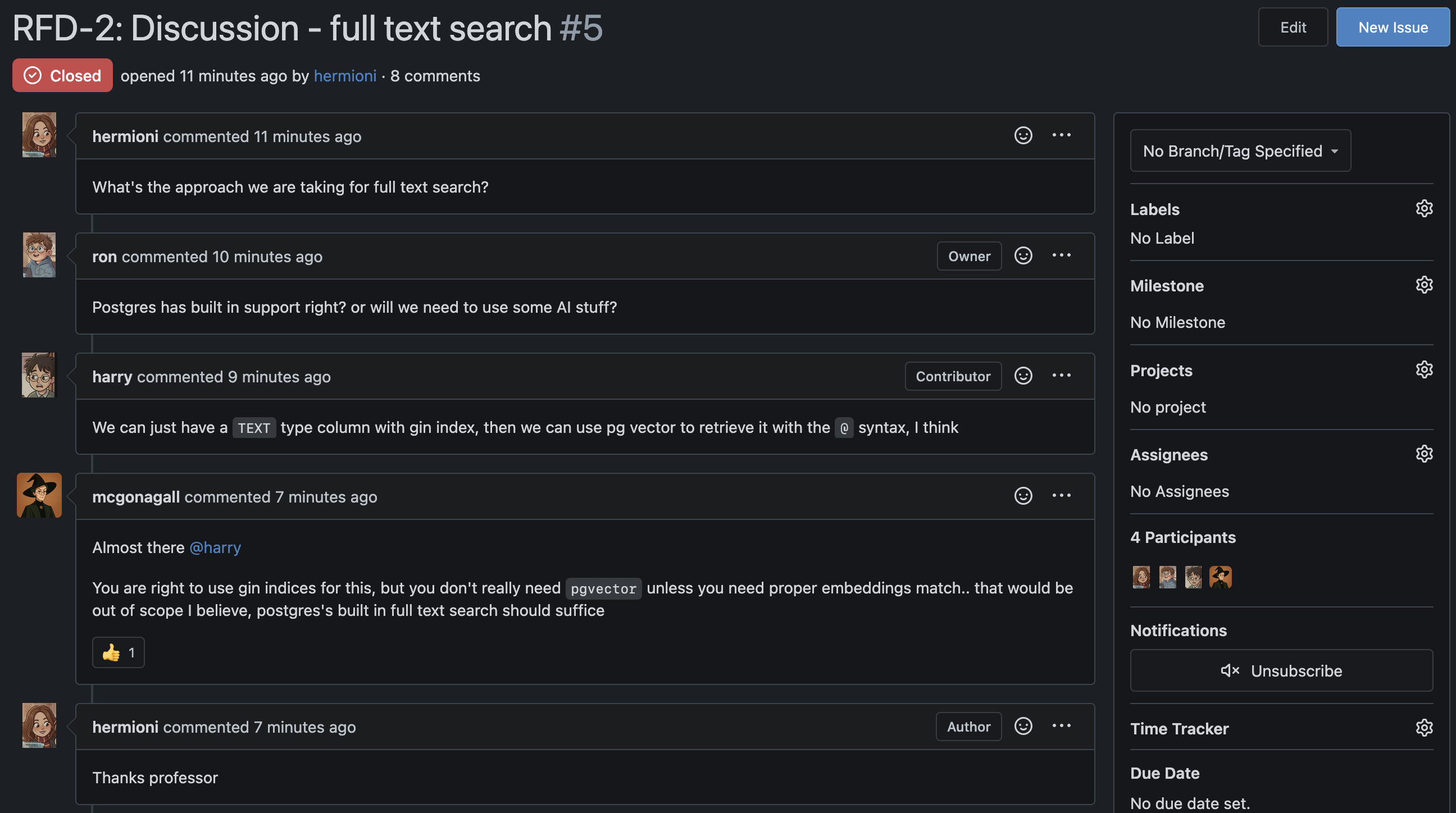
Non code contributions, triaging
The professor weighed in as well
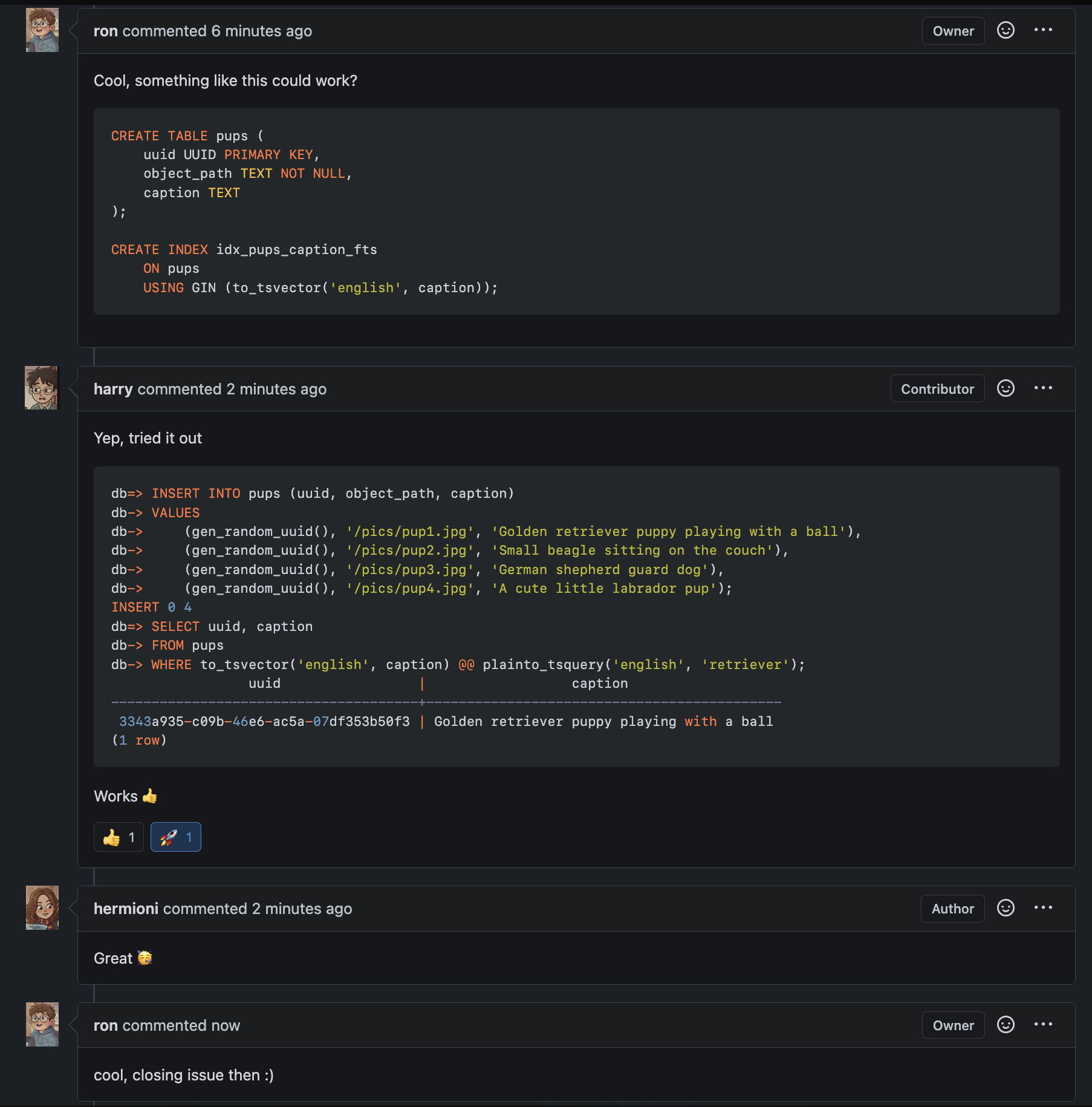
They decided on the approach and came to a conclusion to use postgres’s gin index and full text search capabilities
Ron then went and coded this up, while Hermioni worked on the UI in another fork
First, he wrote the sqlc config file, schemq and query.sql and generated the database interface in the adaptors package with sqlc generate
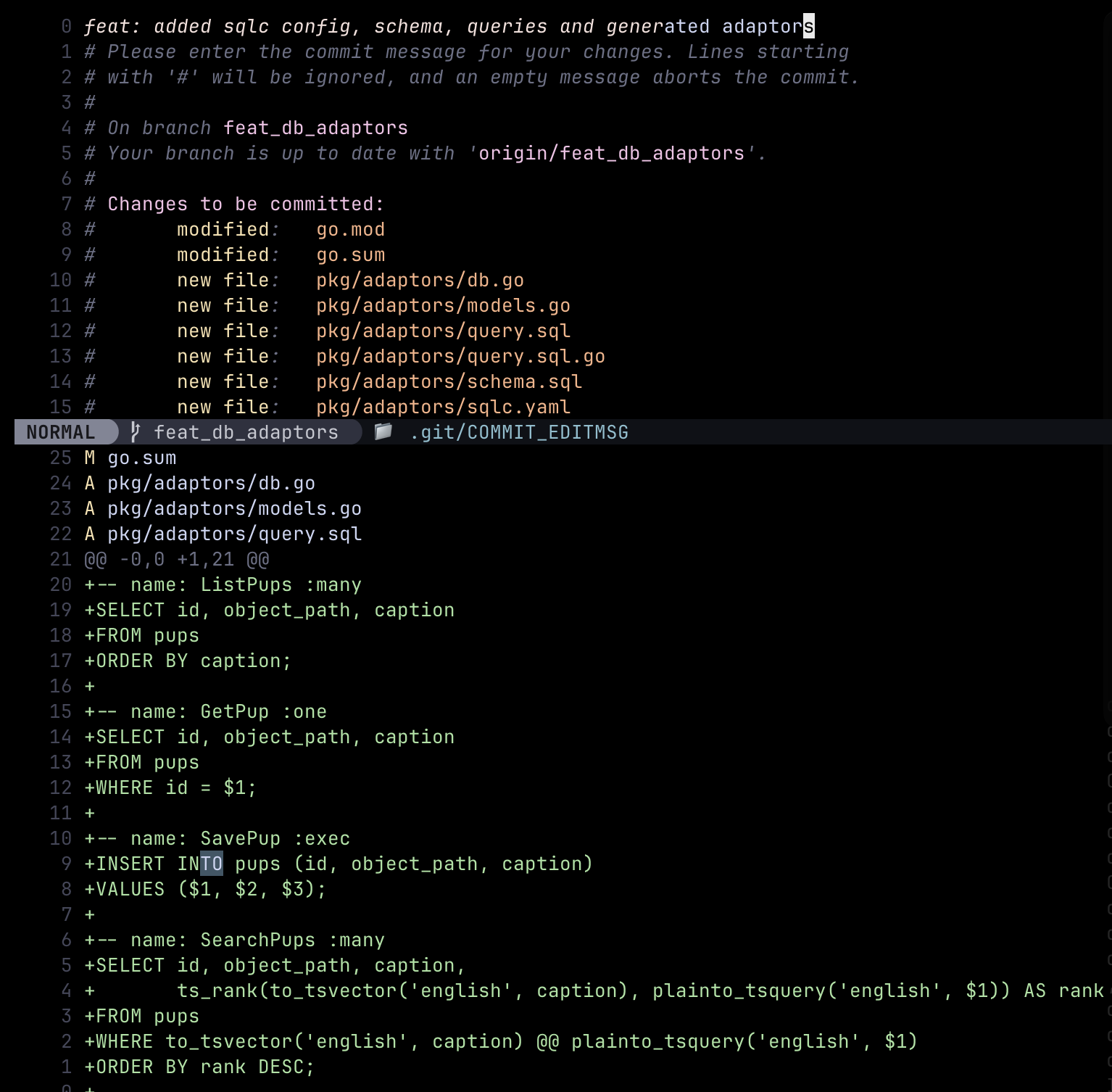
Note: if the specifics of the code here are foreign to you, that’s okay… this might as well have been an orm.
Going into the details to keep the scenario real :)
Now he can finally write the handler logic for the API’s. Once done with part of the implementation, he starts a draft pull request, by adding a WIP prefix marking it as work in progress.
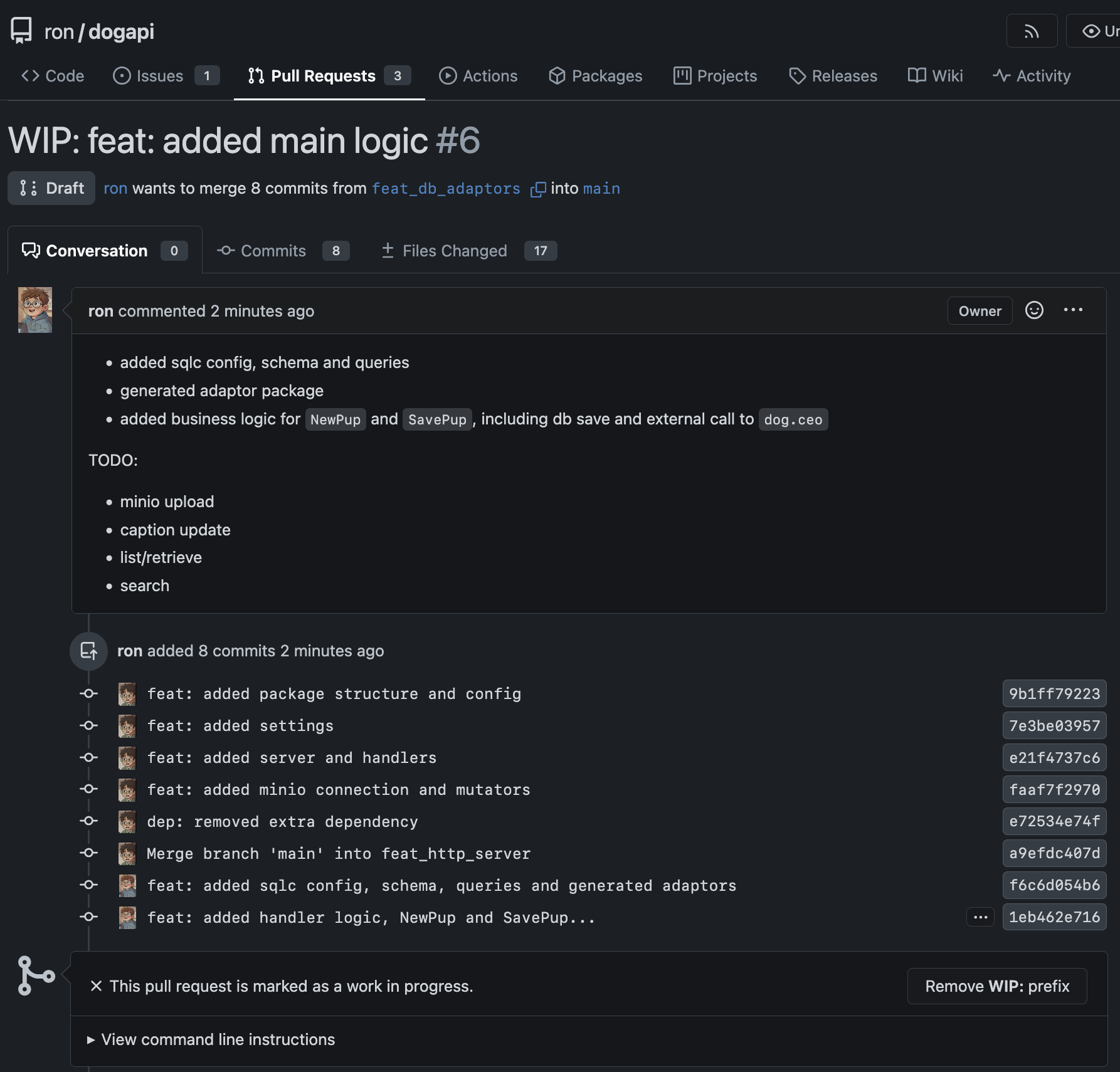
Note how he clearly wrote down the pending items, that he can refer for subsequent work. Having this also lets others weigh in, and contribute to the same PR
Meanwhile, they can peer review each the open PR’s and merge accordingly
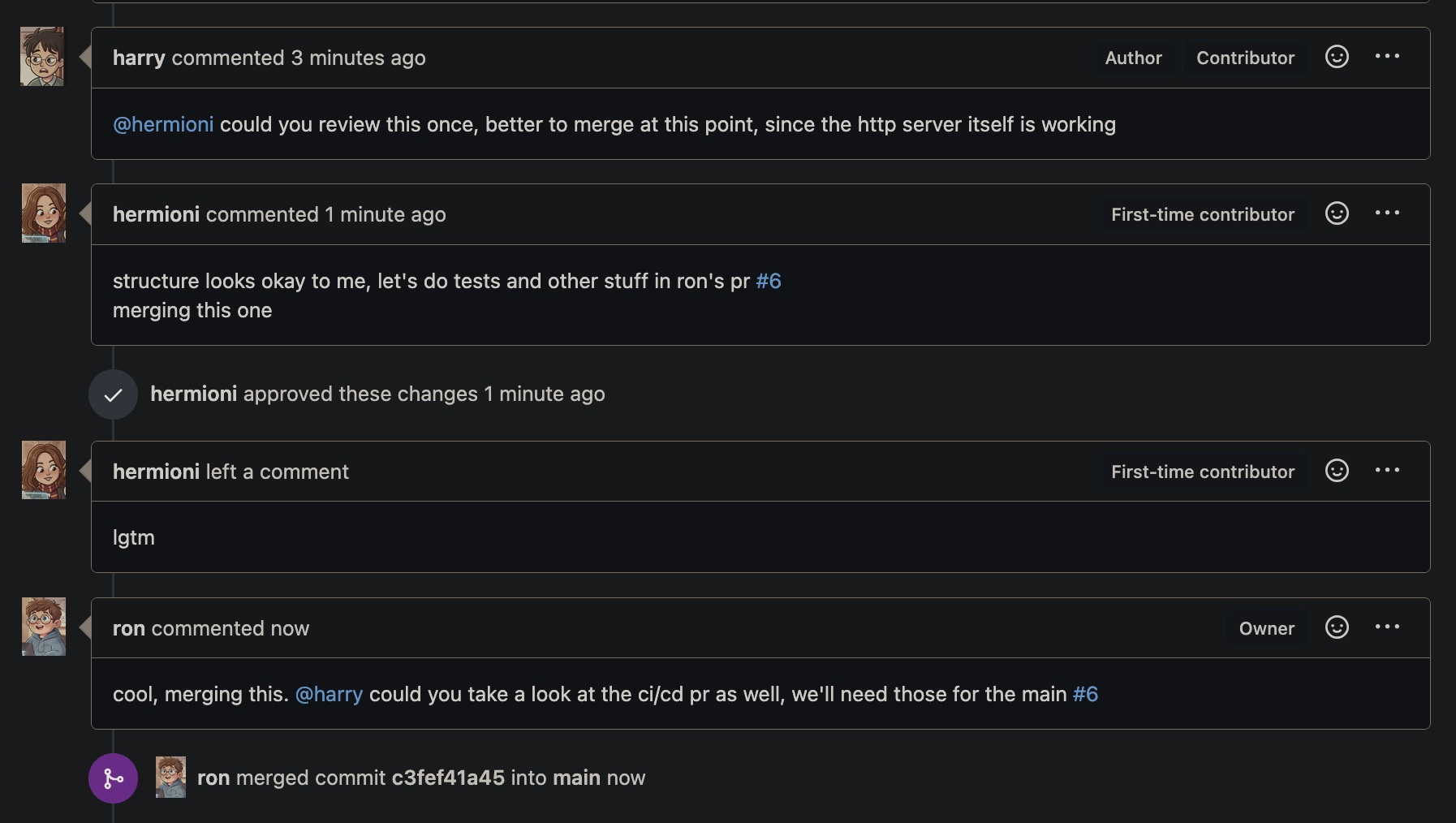
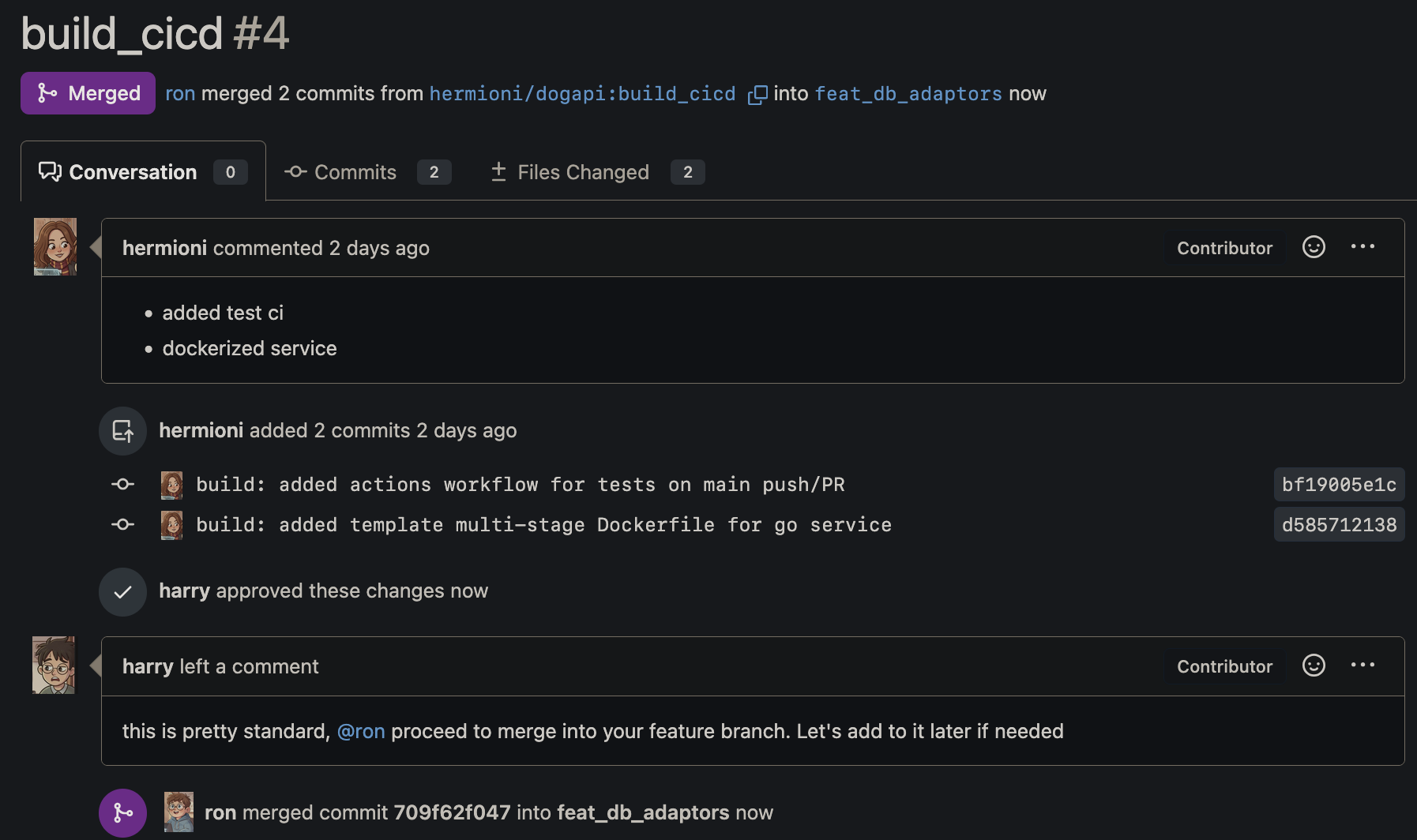
See how things can happen asyncronously here… Though for a small team like this one, it would have made more sense to merge certain stuff sequentially, e.g. the ci/cd PR, but in a larger team, decoupling dependencies definitely helps in the long run, though at the end of the day, it’s still up to developer/team to decide how they want to do things
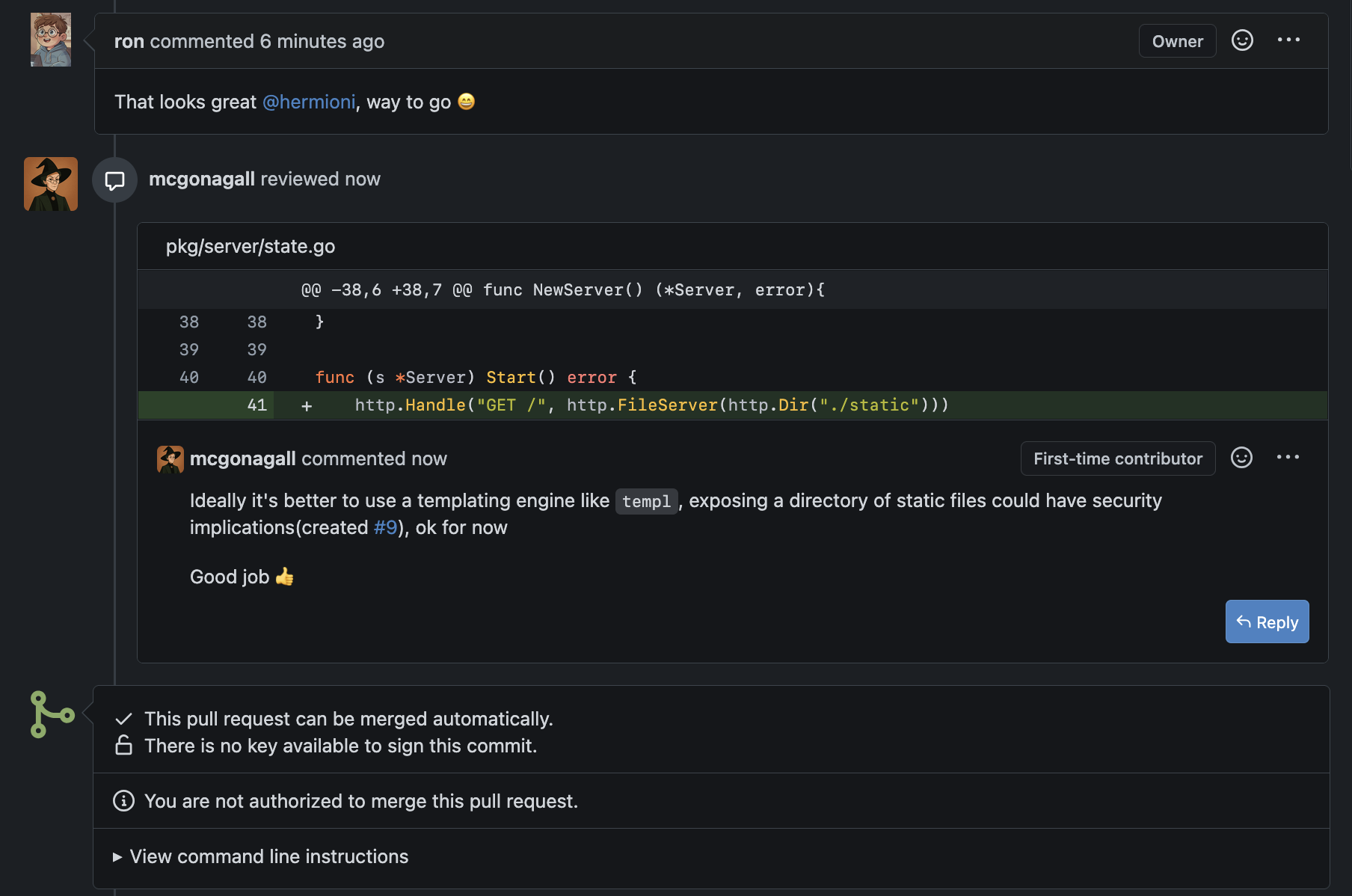
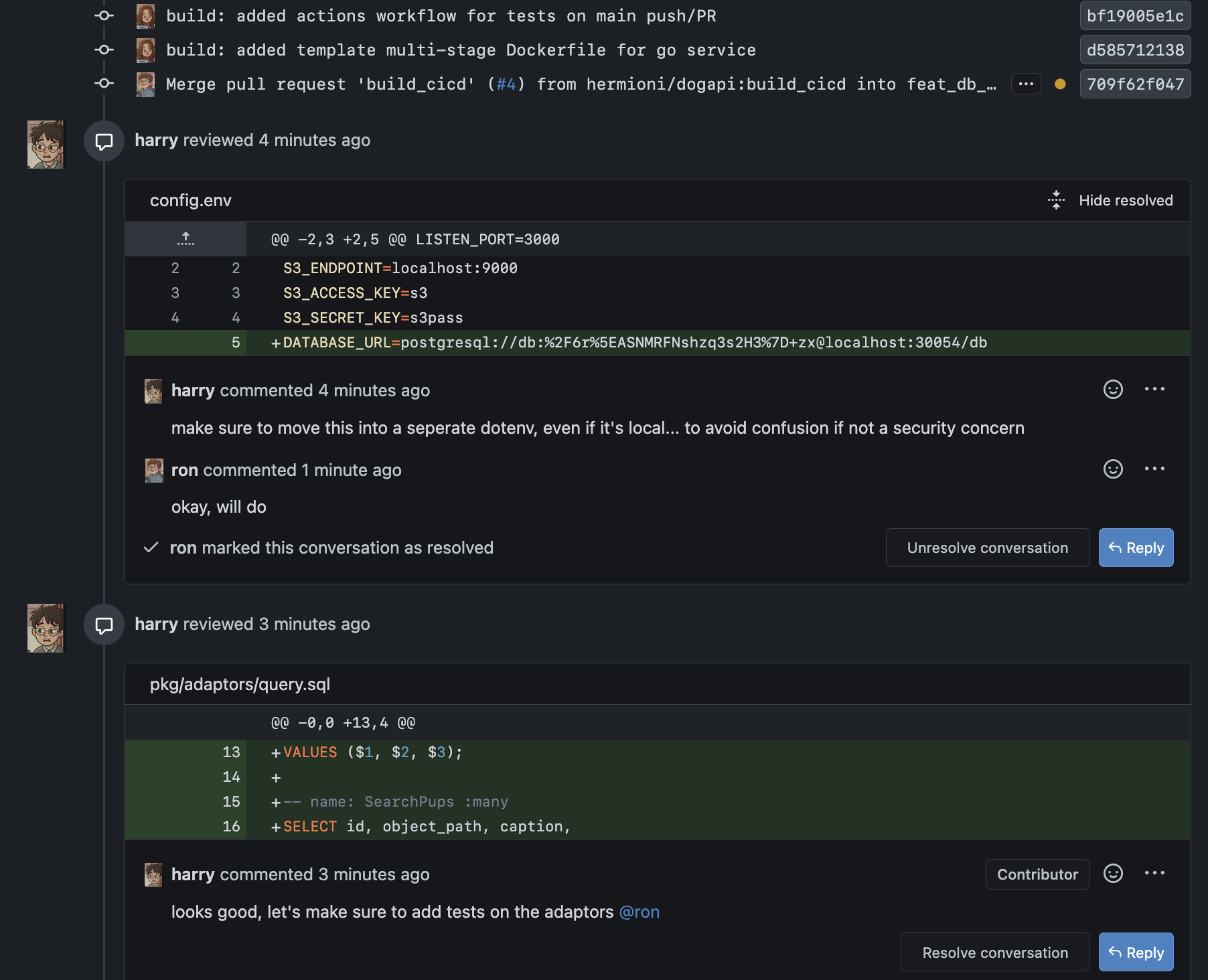 Meanwhile, harry reviewed ron’s code and left a few comments.
Meanwhile, harry reviewed ron’s code and left a few comments. 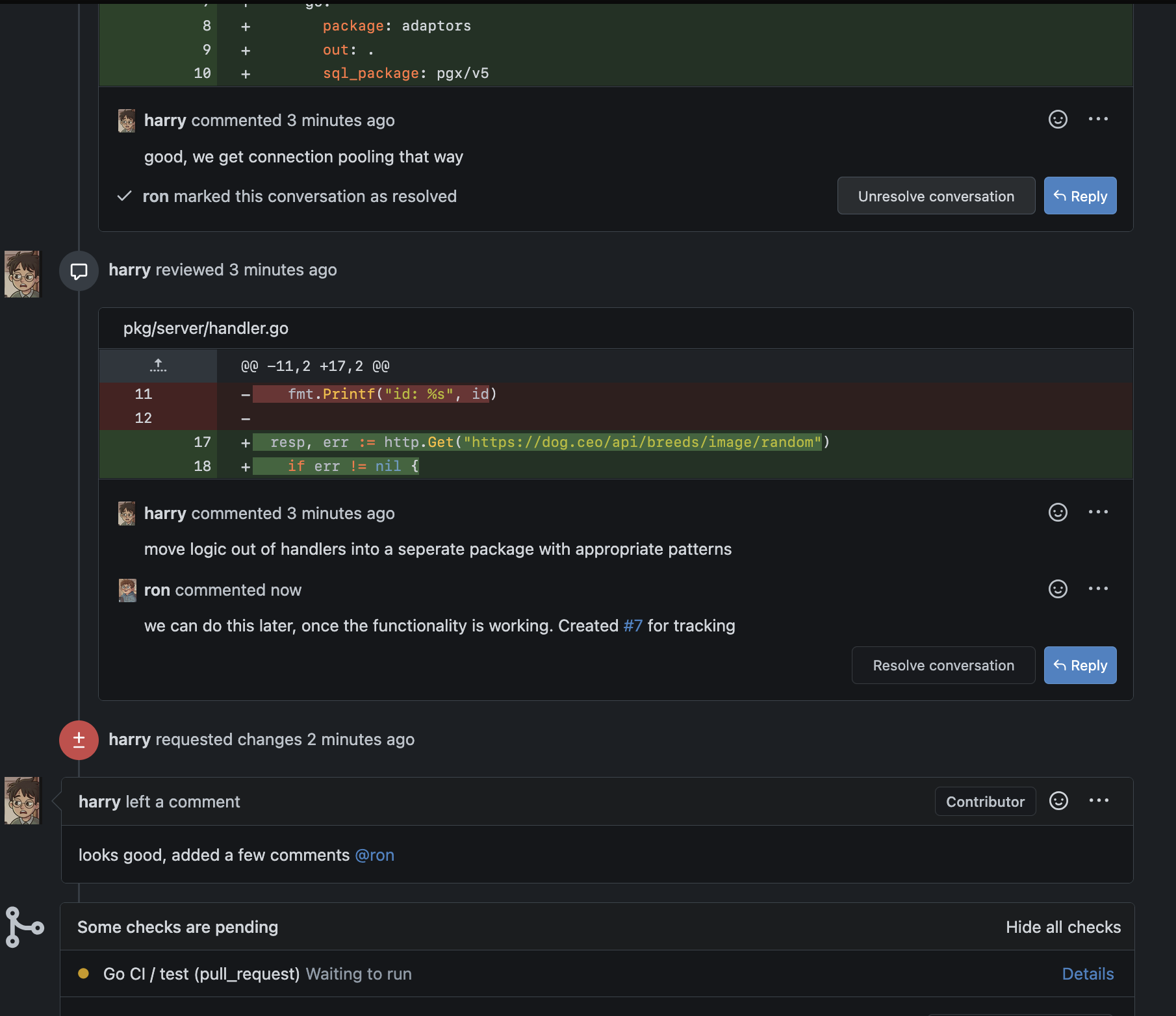 Ron accepted the ones immediately actionable, and marked the less urgent ones for future work with a new issue for tracking purposes
Ron accepted the ones immediately actionable, and marked the less urgent ones for future work with a new issue for tracking purposes
On the other hand, Hermioni kicked off a frontend screen as per the spec in a seperate feature branch 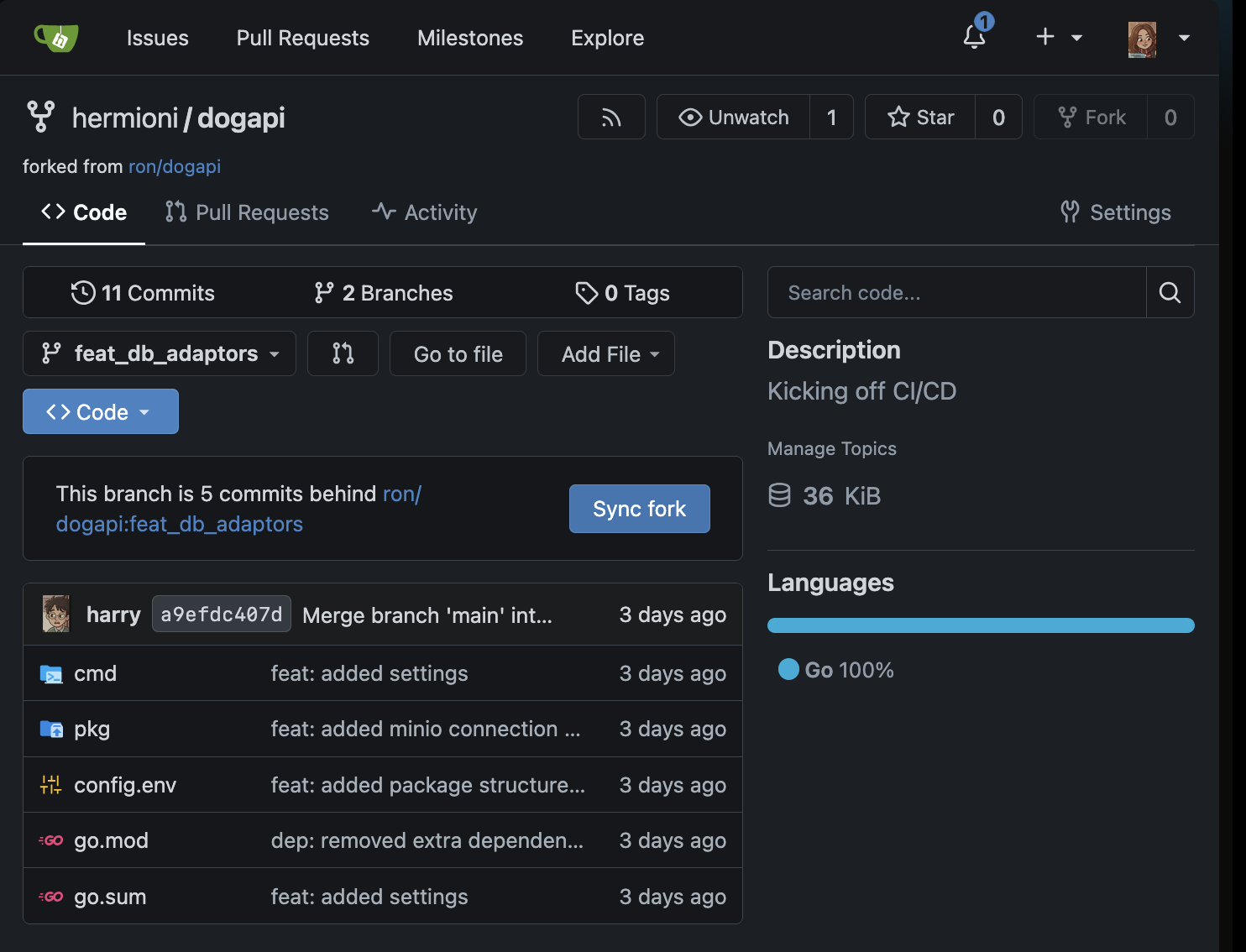 She chose to go with a static html with
She chose to go with a static html with alpineJS for rendering so that they don’t need to have a seperate frontend container with something like react 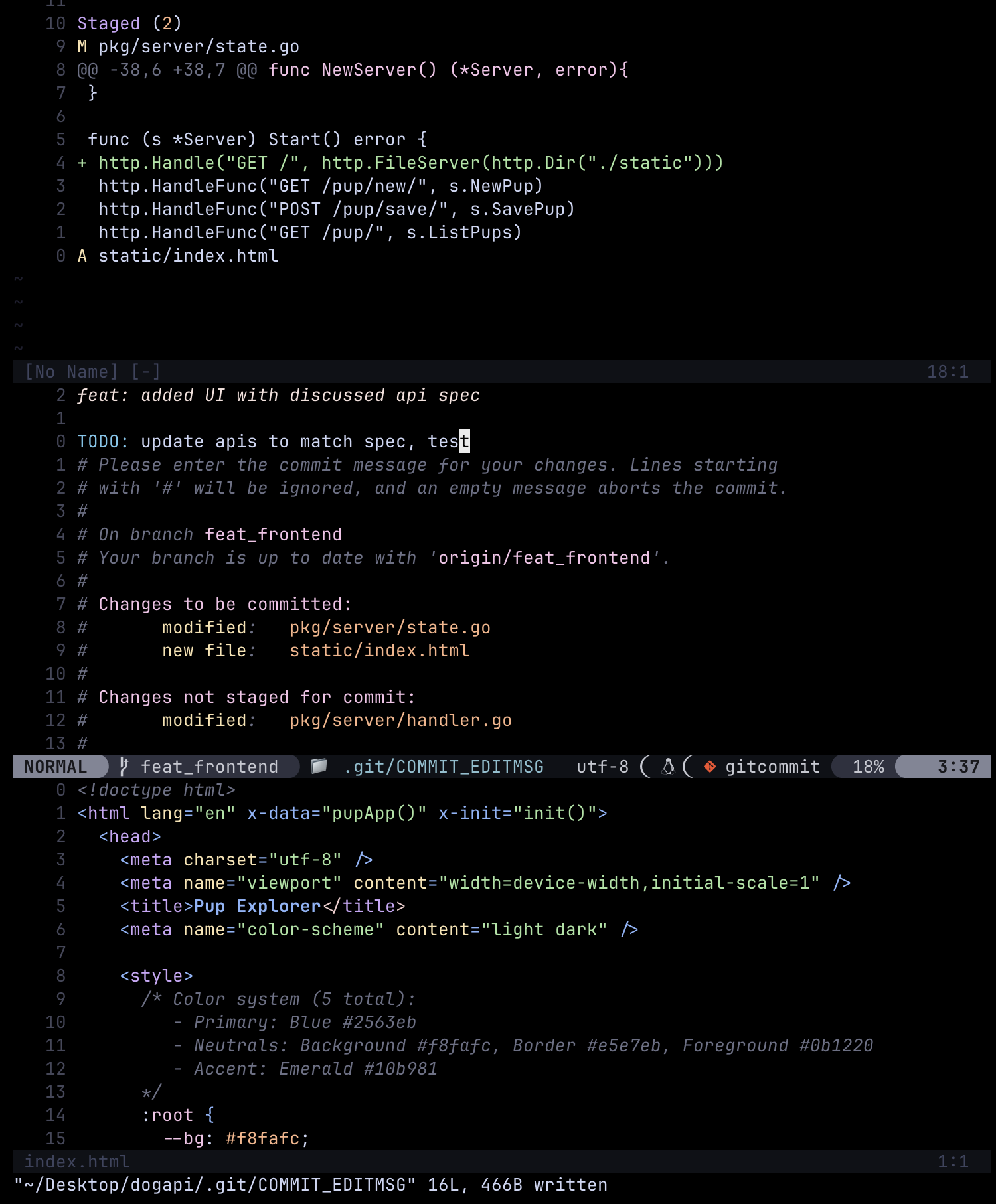 There was a mismatch in the api functionality since ron is not yet done updating it to the new spec, so she left a TODO comment for ron and raised a PR
There was a mismatch in the api functionality since ron is not yet done updating it to the new spec, so she left a TODO comment for ron and raised a PR 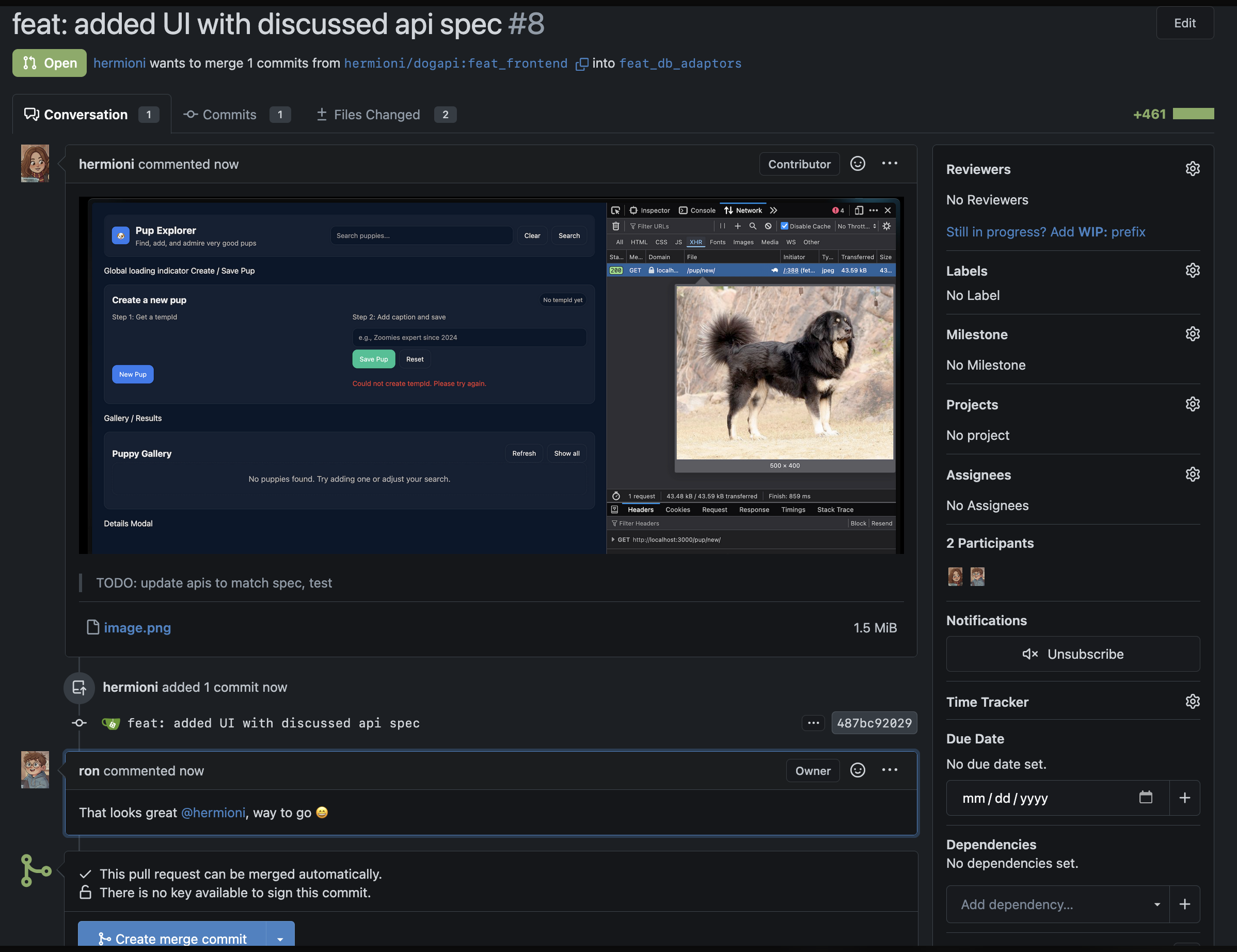
The prof pointed out a potential issue with the static files approach, created an issue for the same
They then went on to do this for a few weeks and got the site working, complete with github actions for tests and other CI and deployed it to a small VPS, I leave that for you to do… or maybe a future blog 🙃
Conclusion
P.S. There are a plethora of git workflows like rebase over merge, git bisect, etc that can improve your life, this article turned out to focus more on the collaboration and process aspects,
TODO:I’ll get to that in a future blog, mostly… 😉
At the end of the day, git isn’t just about pushing and pulling code — it’s about collaboration. Ron, Harry, and Hermioni could’ve just hacked things together on one laptop, but by setting up proper repos, PRs, issues, and reviews, they ended up building something in a way that actually scales.
Sure, you don’t always need every best practice for small projects with friends — sometimes it’s fine to merge quick fixes and move on. But as soon as your codebase grows, or more people get involved, you’ll thank yourself for having clean workflows, signed commits, and a habit of writing down your thoughts in issues and PRs.
The important part? Git lets you work asynchronously, without blocking each other. Good practices around commits, branches, and reviews don’t slow you down — they keep the team sane, the history clean, and the project maintainable.
So whether you’re Ron starting out, Harry adding features, or Hermioni keeping things structured, the magic really comes from using git as more than just a backup tool — but as the backbone of teamwork.